


By Delphine Dallison, Wikimedian in Residence at the Scottish Libraries and Information Council (SLIC)
At the beginning of July, I attended the Celtic Knot 2018 conference at the National Library of Wales in Aberystwyth organised in partnership with Wikimedia UK. As a Wikidata novice, but enthusiast, I was excited to see that the conference had an entire strand dedicated to how Wikidata can be used to support minority language Wikipedias. As the new wikimedian in residence at the Scottish Library and Information Council, my hope was to shore up my own knowledge and skills in that area and both pick up some tips on how I could encourage librarians to work with Wikidata with their collections as well as some tools which would allow librarians to work on improving the Scots Wikipædia and the Gaelic Uicipeid.
My first positive impression of the Wikidata strand of the conference was that the presenters made no assumption of prior knowledge, thus making Wikidata accessible to the most novice of us attending the conference and so I will begin this post in much the same fashion with a basic introduction to Wikidata.
What is Wikidata?
Wikidata is a repository of multilingual linked open data, which started as a means to collect structured data to provide support for Wikipedia, Wikimedia Commons and the other wikis of the Wikimedia movement, but has since evolved to support a number of other open data projects.
Wikidata is a collaborative project and is edited and maintained by Wikidata editors in the same fashion as Wikipedia. The data collected in Wikidata is available under a CC0 public domain license and is both human and machine readable which opens it to a wide range of applications.
Data in the repository is stored as items, each with a label, a description and aliases if relevant. There are currently upwards of 46 million data items on Wikidata. Items are each given a unique identifier as a Q number (ie. Douglas Adams is Q42). Statements help expand on the detailed characteristics of an item and consist of a property (P number) and a value (Q number). Just like in Wikipedia, each statement can be given a reference, so people using the data can track where it was sourced from.
Based on the example below, one of the detailed characteristics of Douglas Adams is that he was educated at St John’s College. To translate the sentence Douglas Adams (Q42) was educated (P69) at St John’s College (Q691283) into data, you could portray it like this:
| Item | Property | Value |
| Q42 | P69 | Q691283 |
| Douglas Adams | Educated at | St John’s College |

How can Wikidata support minority language Wikipedias?
As previously mentioned, Wikidata is a multilingual repository which supports all the languages supported by Wikipedia. Although English is the default, users can set their preferred language in the Preferences menu after logging in. Each Qnumber item on Wikidata has both a label and a description and you can select each one and see how many languages the label is translated into. The same principle works for properties. Wherever there isn’t a translation available for a label, description or property, it will revert back to English.
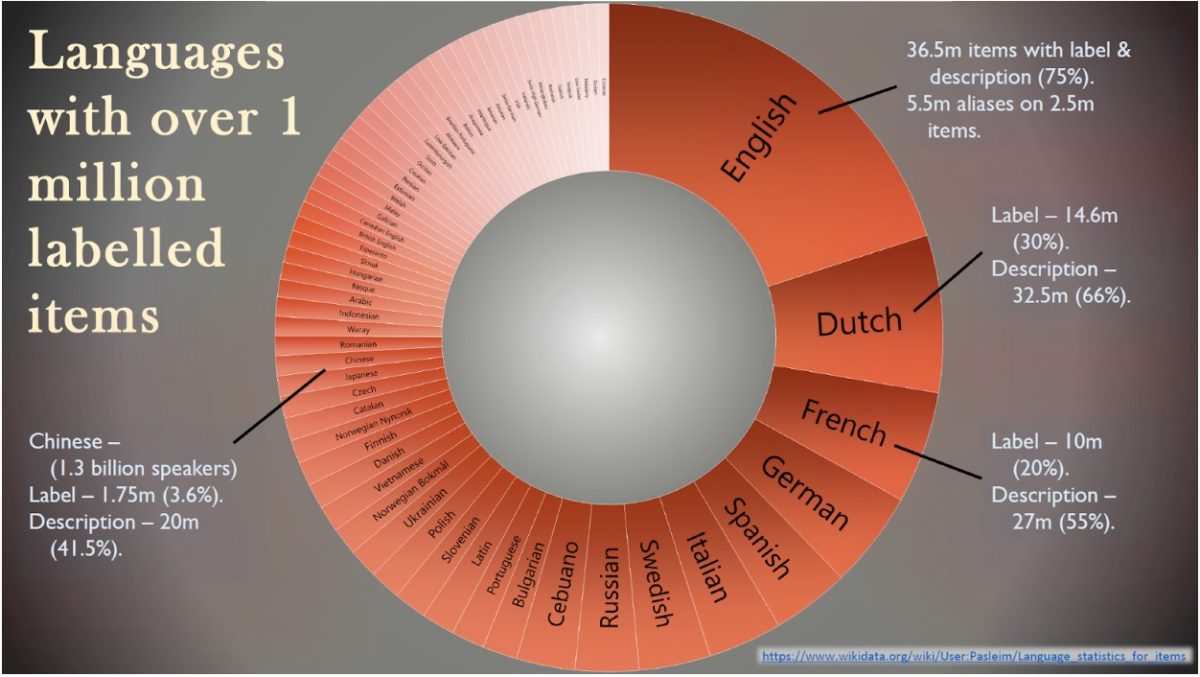
During the conference, Simon Cobb, visiting Wikidata scholar at the National Library of Wales, gave us an overview of the language gaps on Wikidata. As you can see from the graph below, the English version of Wikidata has 36.5 million labels (equivalent to 75% of the content held on Wikidata). After English, the figure quickly drops to 14.6 million labels for Dutch, 10 million for French and 8.7 million for German. UK minority languages such as Welsh, Scots and Scottish Gaelic average just over 1 million labels in their respective languages (just over 2%), meaning that all items without a translated label will automatically revert back to English or to the item’s Qnumber.

If we want to improve accessibility for minority languages on Wikidata, it is essential that we get more editors translating labels in their preferred languages so we can get a better representation of all languages on Wikidata. To help with this, Nicolas Vigneron, from the Breton Wikipedia, demonstrated how you can use the Translathon tool to quickly produce lists of labels missing in your language and add the translations directly in Wikidata by selecting the Qnumber you wish to translate. A new tool has since been developed on the same principle, the Wikidata Terminator, which gives a greater range of languages to work with.
Why translate labels on Wikidata?
You might be thinking that translating labels is all well and good for giving a better language representation on Wikidata, but how does it benefit editors who prefer to work on content on their language Wikipedia? We know that minority language communities are often small and disparate. Volunteer fatigue is a real and constant challenge, so why would you want to divert their efforts to translating labels on Wikidata rather than adding content to Wikipedia? The content held in Wikidata is human and machine readable. This is important because it means that using coding and tools, we can use Wikidata to automatically generate content on Wikipedia. A few of those tools were presented at Celtic Knot 2018.
Hady Elsahar gave us an introduction to the ArticlePlaceHolder tool. The concept behind this tool is that rather than having red links in their language Wikipedia to indicate articles that need created, editors can quickly and easily create a place holder for the article with content generated from Wikidata. The place holder would feature an image if available and a collection of statements associated with the item. The benefit to the reader is to be able to access pertinent information on a topic in their own language, thus relieving some of the strain on small communities of editors. The ArticlePlaceHolder can also be an incentive to new editors to create an article based on the facts available from Wikidata and supplement it with their own secondary research on the topic.

Pau Cabot also ran a workshop on how to automatically generate infoboxes on minority language Wikipedias by drawing the data from Wikidata. Infoboxes predate Wikidata and already foster a symbiotic relationship between Wikipedia and Wikidata. Wikipedia’s infoboxes hold basic data on a topic that is formatted to be compatible with Wikidata so they can be harvested to enrich Wikidata. However, a new trend is currently looking at how we can use Wikidata to generate the information displayed in Wikipedia’s infoboxes. This process can involve some structural work from admins on the Wikipedia’s infrastructure since each language Wikipedia have autonomy to curate infoboxes and other tools based on the wishes of their community. Pau Cabot talked us through the process that his admin team on the Catalan Wikipedia followed to decide on the infobox categories they would use across their Wikipedia, narrowing it down to a list of 8. Once the infrastructure was in place, the admins were able to generate easy templates that could be added to any relevant article and would automatically generate an infobox filled with data derived from Wikidata. Wherever the data’s labels do not currently exist in Catalan, the labels revert to the closest language available (Spanish if available, English as a last resort). However, the infoboxes also each offer the reader an easy edit tool, which allows the reader to translate the label directly in the infobox, whilst automatically adding the translation to Wikidata. This tool can therefore make the translation of labels accessible to Wikipedia editors who might not necessarily find their way onto the Wikidata project.
How can minority language communities contribute their own content to Wikidata?
Everything that we have discussed so far has been focused on how you can draw data from larger language Wikipedias to translate and add to smaller language Wikipedias, but of course minority language communities don’t simply want a Wikipedia that is a translated copy of the English Wikipedia. One of the chief objectives of the minority language Wikipedias is to act as repository of their own cultural capital and I would argue that working with Wikidata can only enhance the visibility of that culture. We need to start developing strategies with GLAMs and academic researchers to add more data on minority language cultures to Wikidata.
The National Library of Wales has already been doing work in this area and after adding 4800 portraits from their Welsh portrait collection, they also added all the associated metadata to Wikidata. This work was carried out in partnership with their national wikimedian in residence Jason Evans and their visiting Wikidata scholar Simon Cobb.
The idea of working with large sets of data and contributing them to Wikidata can seem daunting, however I was most inspired by the introduction that Simon Cobb gave us to the OpenRefine tool during the unconference sessions run on day two of Celtic Knot. OpenRefine is a tool developed by Google to help clean up messy data and in more recent editions of the tool (version 3.0), it has extensions added which allow the users to reconcile and augment their data with Wikidata as well as edit data directly in Wikidata and upload reconciled datasets to Wikidata.
As part of my residency with the Scottish Library and Information Council, I can definitely see the applications for this kind of tool to openly share the metadata on some of the Scots and Gaelic collections held in libraries across Scotland. I plan on testing the concept soon with a collaboration currently in development with professor Peter Reid from Robert Gordon University who is designing a Doric literature portal thanks to funding from the Public Library Improvement fund. Out of this collaboration, we hope to enrich the data available in Wikidata on Doric literature and Doric authors as well as create/improve articles on the topic in both the Scots and English Wikipedias. I hope to see more of these types of projects emerge in the future.
One thought on “Celtic Knot 2018 – How can Wikidata support minority language Wikipedias”