


This article is by Wikipedia administrator User:TheSandDoctor
Early this past December, I was reviewing article submissions on Wikipedia and noticed that some included templates, pages created to be included in other pages, that were inappropriate for pages that are not yet articles. This got me thinking, how widespread is this misconception? A search led to the discovery that there were over 500 — roughly one percent of the 42,939 drafts. While this is indeed a small percentage, that is still over 500 drafts which may result in confused new editors.

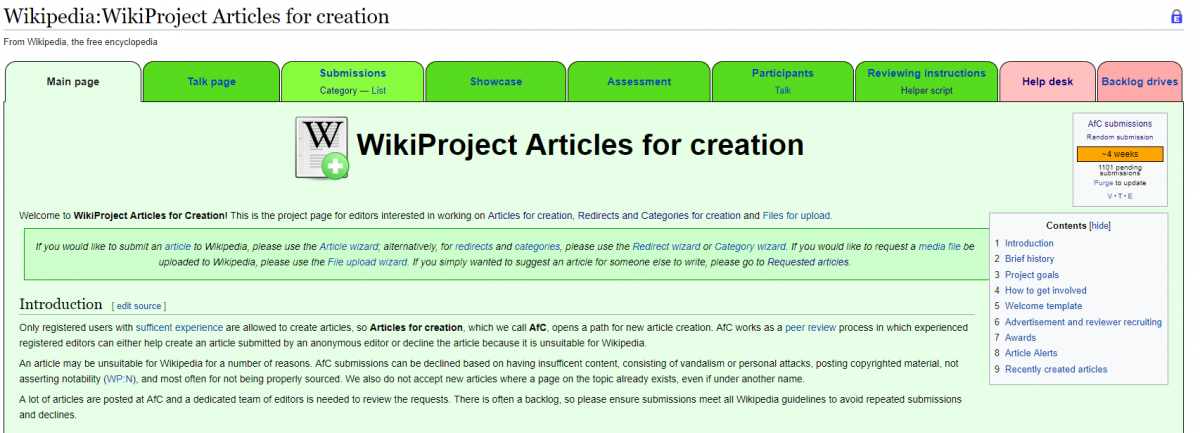
The English Wikipedia consists of 32 namespaces, different sets of Wikipedia pages whose names begin with a particular reserved word recognized by the MediaWiki software. While it would be cumbersome to list them all here, it is worth mentioning the Draft, Main/Article (“mainspace”), and Wikipedia namespaces. The draft namespace is somewhat special as, unlike the others, it is not indexed by most search engines, including Google. This allows it to be a place where editors can develop article drafts that are not yet ready for indexing, may not yet have demonstrated adequate notability, or are notable works in progress. When a draft is deemed ready by an editor with sufficient user rights and experience, it can then be moved to the “main” article namespace, where pages most readers are familiar with are located. Another path by which a draft may make its way to the mainspace is through Articles for Creation (“AfC”), a peer review process in which experienced registered editors can either help create an article submitted by an anonymous editor or decline the article because it is unsuitable for Wikipedia.
An article may be unsuitable for Wikipedia for a number of reasons. AfC submissions can be declined based on having insufficient content, consisting of vandalism or personal attacks, posting copyrighted material, not asserting notability, and most often for not being properly sourced. We also do not accept new articles where a page on the topic already exists, even if under another name.

Articles for Creation is consistently backlogged with sometimes more than 2,000 drafts awaiting review. Any editor whose Wikipedia account is at least 90 days old, has made 500 edits to articles, has good understanding of the various notability guidelines, and agrees to review solely on a volunteer basis may apply to become a reviewer. It is important to note that despite the constant backlog, submissions must be carefully reviewed for whether or not they meet the criteria. However, in the case of those which meet any of the quick-fail criteria, the total time investment is much lower.
In order to speed up the number of submissions reviewed while maintaining review quality, the number of active reviewers must increase. If you are interested in helping out and have had an account for more than 90 days with over 500 total edits, you can find out more and how to apply here.

By its very nature, the pages within the draft namespace are designed to be separate. They are not permitted to be active members in categories nor are they permitted to be linked to within existing articles as doing so would defeat the purpose of the draft namespace — a workshop or incubator of sorts for new articles. By this very nature, having templates such as “Underlinked” or “Orphan” — both being designed for articles, not drafts — present could confuse new contributors as to its purpose, potentially giving incorrect information.
“Underlinked” refers to having too few incoming links from existing articles while “Orphan”, in the Wikipedia context, refers to having no incoming links from articles at all — in essence being orphaned from the rest of the encyclopedia. In articles, both of these are issues that could affect its visibility and discoverability, but for drafts that is the entire point. They are not ready for the spotlight that is indexing; if they were, they should not be in the namespace to begin with or should have been moved out of it already.
I have worked on three bots so far, each with vastly different purposes and two of the three performing multiple tasks. Unlike the others, TheSandBot is the most multipurpose. As was previously written about for Wikimedia UK, the bot’s first task was a temporary one moving articles and other pages.
With this in mind and armed with the statistics, — one percent is still far too high — I got to work on the second task for TheSandBot. The sole purpose of this task is to look for templates which should not be in drafts and remove them if present. So far, the bot only looks for the following four templates and any of their aliases (too many to list), but more could be added with minimal effort.
{{orphan}}
{{uncategorized}
{{underlinked}}
{{unreferenced}}
As of 17 December 2018, the task has been approved and is now set as an automatic cron job, running daily at 03:00 UTC (3am UTC, 7pm Pacific, 10pm EST). This task is different than all the rest that I have worked on. Whereas my others, while lacking a fixed start or end date, were temporary, this is my first task without an end date at all. So long as there is a need and this task is not shut off, it will run at that time for the rest of time.
I am not too sure where my bot work will take me next, but I am definitely excited for the future possibilities. Maybe I will finally be able to take over the Good Article review clerking duties from Legobot, which the current operator wishes to partially retire. Either that or I might find something else that needs fixing. Something always needs fixing on a project the size of Wikipedia. One thing I do know for sure though is that, at over 270,000 combined edits, my bots are closing in on having performed 300,000. This will most likely happen later this year.
_______________________
If you’re a developer working on the technical side of Wikimedia projects, there is a community of developers in the UK you can get help and advice from. Wikimedia UK will be running Wikidata meetup events every couple of months in London, and the best way to find out how to get involved in improving the Wikimedia projects is by talking to other developers. We also encourage Wikimediand to write for our blog about their work to encourage others to get involved. So get in touch if you have ideas!




























{kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}