The winners of the UK section of the world’s biggest photo contest Wiki Loves Monuments have just been announced, with the judges awarding fIrst prize to this stunning image of Gloucester Cathedral cloisters taken by Christopher JT Cherrington.
Chris has written a short blog post on the Wiki Loves Monuments website explaining how he took his winning image.
The 2018 contest
Wiki Loves Monuments is the world’s biggest photographic competition, with a total of 260,607 images submitted to the 2018 competition from all over the world. In the UK, 13,185 images taken by over 500 photographers were entered. The competition aims to gather high quality, openly-licensed images of historic sites from all over the world.
The contest is an incredible opportunity to document and preserve our heritage for future generations, and this year saw a particular focus on the capture of internal shots, as well as of those sites which were lacking a freely-licensed image in Wikidata, the knowledge base which sits behind Wikipedia.
Among this year’s winners are three castles (all in Wales), two lighthouses (New Brighton and Bass Rock), and one museum (Arbroath).
This year saw a marked increase in submissions from Scotland, with over double the number of entries submitted this year than in 2017. Wikimedia UK worked with Historic Environment Scotland’s publicly-available database of listed buildings and scheduled monuments to add over 27,000 new eligible items to Wikidata, vastly improving the coverage of Scotland.
PIctures submitted to this year’s contest are already being used to illustrate Wikipedia articles, and Wikimedia UK would like to extend their warmest thanks to all those who submitted entries, helping to significantly improve access to this knowledge.
The top ten UK winners now go forward to the international judging stage of the contest, where they will compete against the best images from some 55 other countries. The first, second and third placed UK winners receive £250, £100, and £50 respectively, with seven Highly Commended winners receiving £25 each.
Additional prizes have been awarded for the best three images from England, from Scotland and from Wales. Archaeology Scotland has also sponsored a special prize for the best photograph of a site in Scotland: a free 1-year membership including the Archaeology Scotland Magazine as well as access to their learning resources.
One of the competition’s judges noted that the quality and variety of images submitted continues to increase:
“Each year the standard of entries for Wiki Loves Monuments UK rises. Browsing through the long list of almost 250 images was made enjoyable and easy because of the quality of the images and the variety of locations from across the British Isles on display, narrowing it down to a shortlist of just 10 was a much harder process. It is a real pleasure to have been involved in the judging of this competition and to see the skill and dedication of the winning photographers recognised.”
The most prolific photographer of “new” UK historic sites was Paul the Archivist, who uploaded more than 200 pictures of sites which hadn’t previously been represented in the database.
For the complete list of the UK award winners and shortlisted images, well as access to high-resolution copies, see the winners’ page on Wikimedia Commons.
Image from UK Black Tech’s stock photo project to increase Open Licensed photos of black people in business and tech – Wikimedia Commons CC BY-SA 4.0
So you’re a business. You’ve got a company that’s number #3 in the UK at making spoons, or something like that, and you want to make sure that when people search for your company, they can see you’re legit because a Wikipedia page confers an aura of legitimacy on your noble pursuit of creating the best spoons in the land.
You tried to make a page for your spoon business before, but for some reason it disappeared. No doubt the anti-spoon lobby have got their knives out for you in their cynical attempt to stop people using your quality products. You’ve found the charity responsible for Wikipedia in the UK (that’s us!) and you want to know how you can get your spoon business listed on Wikipedia.
I’m afraid that we may have some bad news for you. You see, Wikipedia is not a business directory. It’s not the Yellow Pages or whatever website has put the Yellow Pages out of business. So you probably need to stop and think ‘is my business notable enough to be in an encyclopaedia?’ It’s estimated that there are somewhere around 200 million companies in the world, so only very few of these will be famous enough to appear in an encyclopaedia.
Maybe you don’t know the answer because you’re not sure what makes something notable enough to be on Wikipedia. Well, luckily we have a set of Notability guidelines for that.
The basic criteria for notability is that “a topic has received significant coverage inreliable sources that areindependent of the subject”. So I’m afraid that links to your own site, quotes in articles about another subject, or references to other self-published sources like blogs, petitions or social media posts just won’t meet this standard.
A presentation on verifiability and notability – Wikimedia Commons CC BY-SA 4.0
This standard isn’t supposed to be easy to meet. Your business might be doing really well, it might make the biggest spoons in Britain, but if you’ve not had the Times, or at least the local newspaper down to cover your amazing spoon production in an article which is specifically about your business, then as far as Wikipedia is concerned, it’s not going to be notable enough. But don’t get disappointed. If you want your spoons to be famous, you need to concentrate on getting some media coverage for those spoons. Wikipedia can only cover what has been already published elsewhere.
If your company is notable, it’s likely that someone will eventually get around to creating a page for it. You’re just going to have to be patient. If you try to create the page yourself, without really understanding the core rules of Wikipedia, you might make some mistakes, like putting in Non-Neutral Point of View language, which will show others that you might be connected to the subject matter, and result in the article’s deletion for Conflict of Interest (CoI) editing.
You should also most definitely not pay someone to create a page for you. Paid editing, without a declaration that someone is being paid to edit, is against the rules. If the page for a company keeps getting made and then deleted, editors may ban the creation of the page indefinitely. In 2015 Wikipedia editors uncovered a group trying to make money by scamming businesses by telling them they could make and protect their company’s Wikipedia articles.
The main lesson in this is that if you are going to use Wikipedia properly, you really have to understand how it works. You can’t just stumble into it and start changing important things without appreciating what you’re allowed to change and what kinds of edits are acceptable. On English Wikipedia, you can’t even create new articles anymore without having a registered account with a certain number of edits.
We recognise that this can be frustrating and offputting to some businesses who could theoretically have good reason to interact with Wikipedia. However, there are things your company could consider doing to make it more likely that someone will create a page for you. You could consider releasing photos of your company or its products under an Open, Creative Commons license, meaning that these photos can be used on Wikipedia.
All the content on Wikipedia is shared on Open Licenses, so we can’t use any media about your company unless you publish it specifically on an Open License. The Welsh music label, Sain Records, released the cover art of many of their Welsh-language records on Open Licenses, along with 30 second clips of some of their artists songs. This means there is now much better coverage of the company and its products on Wikipedia.
A guide to the different types of Creative Commons Open License, and what you are allowed to do with the content published on each one. Image via ANDS.
I have been trying to do outreach to the music industry to encourage them to donate content, like photos of their artists, which Wikipedia editors can use to improve pages on notable musicians. There are lots of black and ethnic minority musicians who don’t have pages on Wikipedia, and we would like to change that. Again, we don’t encourage people who work for music companies to make pages about their artists, but if those companies would like to work with Wikimedia UK, we could organise Wikipedia editing workshops for fans of the artists, and use photos donated by the artists’ companies to create pages for notable people who deserve to be on the encyclopaedia.
We’ve already had a very fruitful collaboration with the Parliamentary Digital Service, who released official parliamentary photos of MPs in 2017, and you will now see that most MPs pages use their official photograph in the infobox on the right of the page.
The best way to learn how Wikipedia works is to get involved. Come to our events. Come to meetups to talk to other Wikimedians and ask their advice. The community is huge, and has over the past 18 years created a complex set of rules to govern the living, constantly changing nature of Wikipedia. We think it’s an amazing achievement, and that’s why we treat it as so much more than an advertising platform.
By Charles Matthews, Wikimedian in Residence at ContentMine
With the end of October, Wikidata’s birthday comes round once more, and on the 29th it will be six years old. With the passing of time Wikimedia’s structured data site grows, is supported by an increasingly mature set of key tools, and is applied in new directions.
Fundamental is the SPARQL query tool at query.wikidata.org, an exemplary product of Wikimedia Foundation engineering. But I wanted to talk here about its “partner in crime”, the QuickStatements tool by Magnus Manske, which is less known and certainly comparatively undocumented. QuickStatements, simply put, allows you to make batch edits that add hundreds or thousands of statements to Wikidata.
So QuickStatements is a bot, but importantly you don’t need to be a bot operator to use it. You do need to have an account on Wikidata (which is automatic if you have a Wikipedia account). And you do need to allow QuickStatements to edit through your account. That can be carried out by means of a WiDar login. For that you simply need to go to https://tools.wmflabs.org/widar/ and click the button.
So far, so good. Now we need to look at your “use case”: the data you have that you think should be in Wikidata. How is it held, and how far have you got in translating it into Wikidata terms? Are you envisaging simple Wikidata statements, or are you reckoning on adding qualifiers, or references, or both? One of the issues with the documentation I come across is that “or both” may be the underlying assumption, but it can make it harder to see the wood for the trees.
Charles Matthews and Jimmy Wales at Wikimania 2018 – Wikimedia Commons CC BY-SA 4.0
A further question that is fundamental is whether you are adding statements to existing items, or creating new items with statements. In the first case, without qualifiers or references (though referencing matters greatly, on Wikidata as on Wikipedia), we can say straightforwardly that you’ll need three columns of data. At the very least, understanding this case is the natural place to start.
Let the first column be the items you’ve identified that need to have statements added. Getting this far may indeed be the most important step. If you have a list of people, or of places, they need to be matched correctly to Wikidata Q-numbers. Proper names are very often ambiguous: for example Springfield shows 41 places called Springfield (where fictionally The Simpsons live: the idea that there is one in every state is an urban myth, it turns out). Matching into Wikidata is a cottage industry in its own right, around the mix’n’match tool.
Suppose then you have your first column in good shape. You now need properties (basically predicates in the statements), and either objects, for forming predicates, or other strings, depending on the type of property. For example, if what you have is a list of people born in Birmingham, UK, you need a second column for P19, “place of birth”, and a third column of Q2256. For the population of a place you need P1082, for books where you are adding publication date there is property P577. You always need a second column which is filled with the property code, and then a third column giving the “object” data.
So the assumption is that you are now manipulating the data in a spreadsheet. I find filling a column in Google Sheets can be troublesome, because it wants to increment numbers, so I use a dummy word to fill and then apply find-and-replace.
To avoid disappointment, you also really need to read the instructions, some time or other. These explain that string values such as numbers need to be in “quotes”, but dates need to have a code appended. More spreadsheet skills may therefore be needed, to wrangle the data, but such is modern life.
The payoff comes in being able to paste from the spreadsheet columns into QuickStatements. That introduces the tab characters spoken of in the documentation.
Actually this is not the pro way to use the tool, but does fine anyway: it is officially “Version 1 format” of the “old interface” of QuickStatements2 ,. Under the “Import commands” menu select Version 1, and paste into the “Import V1 commands” box. Click the “Import” button for a preview, and then the “Run” button. You should definitely run a small test first.
QuickStatements runs quite slowly for a bot, taking about a second over each statement. Since the edits are credited to your account, you can see them happening through the “Contributions” link you have when logged in on Wikidata. A top tip is to use the analytics tool, which is easy to do with the property number in the “Pattern” field by setting the approximate times of the run.
There is quite a lot more to learn, obviously. For example, for populations of towns, a qualifier with P585 for “point in time” is the first request anyone would make, and a reference perhaps the second. So more data work, but the same process of creation.
QuickStatements is a workhorse behind numerous other Wikidata tools that create items or add statements to them. In my Wikimedian in Residence work on the ScienceSource project we will use it both on our own wiki to move in text-mining data, and for exporting referenced facts from biomedical articles to Wikidata itself. For more about Wikidata and that project, there is a Wikidata workshop in Cambridge on 20 October.
Donna Watson, Academic Support Librarian at the University of Edinburgh, presenting at the EAHIL Conference Wikipedia editathon – image by Ruth Jenkins
By Ruth Jenkins, Academic Support Librarian at the University of Edinburgh.
For some time, Wikipedia has been shown to be a resource to engage with, rather than avoid. Wikipedia is heavily used for medical information by students and health professionals – and the fact that it is openly available is crucial for people finding health information, particularly in developing countries or in health crises. Good quality Wikipedia articles are an important contribution to the body of openly available information – particularly relevant for improving health information literacy. In fact, some argue that updating Wikipedia should be part of every doctor’s work, contributing to the dissemination of scientific knowledge.
Participants editing Wikipedia at the EAHIL Conference
With that in mind, Academic Support Librarians for Medicine Marshall Dozier, Ruth Jenkins and Donna Watson recently co-presented a workshop on How to run a Wikipedia editathon, at the European Association for Health Information and Libraries (EAHIL) Conference in Cardiff in July. Ewan McAndrew, our Wikimedian in Residence here at the University of Edinburgh, was instrumental in the planning and structuring of the workshop, giving us lots of advice and help. On the day, we were joined by Jason Evans, Wikimedian in Residence at the National Library of Wales, who spoke about his role at NLW and the Wikimedia community and helped support participants during editing.
We wanted our workshop to give participants experience of editing Wikipedia and build their confidence using Wikipedia as part of the learning experience for students and others. Our workshop was a kind of train-the-trainer editathon. An editathon is an event to bring people together at a scheduled time to create entries or edit Wikipedia on a specific topic, and they are valuable opportunities for collaborating with subject experts, and to involve students and the public.
Where a typical editathon would be a half-day event, we only had 90 minutes. As such, our workshop was themed around a “micro-editathon” – micro in scale, timing and tasks. We focused on giving participants insights into running an editathon, offered hands-on experience, and small-scale edits such as adding images and missing citations to articles.
Systematic review editKey stats from the EAHIL editathon
We are waiting on feedback from the event, but anecdotally, the main response was a wish for a longer workshop, with more time to get to know Wikipedia better! There was lots of discussion about take-home ideas, and we hope they are inspired to deliver editathon events in their own organisations and countries. We also spotted that some of our participants continued to make edits on Wikipedia in the following weeks, which is a great sign.
If you want to know more, you can visit the event website which roughly follows the structure of our workshop and includes plenty of further resources: https://thinking.is.ed.ac.uk/eahil-editathon/
Science Source is a new project by ContentMine which builds on their previous work on WikiFactMine, which wanted to ‘make Wikidata the primary resource for identifying objects in bioscience’. This time, they want to automate the process of looking at biomedical research to identify statements that would be useful for improving Wikipedia’s medical articles. They summarise the approach on the grant page for the project:
The ScienceSource platform will be a collaborative MediaWiki site. It will collect and convert up to 30,000 of the most useful Open Access medical and bioscience articles and convert them.
We will work with two Wikimedia communities (Wiki Med and WikiJournal) to develop machine-assisted human-reviewing. The wiki platform will facilitate the decision-making process, driven by the human reviewers.
Articles will be annotated with terms in WikiFactMine (WFM) dictionaries. In this project, those dictionaries will include, for example, diseases, drugs, genes. This not only means that the useful terms are highlighted, but they are also linked to entries in Wikidata and therefore to any relationship that is described in Wikidata. Thus “aspirin” links to d:Q18216 with synonyms, disease targets, chemistry, etc.
Once papers are transferred to standard HTML to get them to the same format for text mining they can be tagged, e.g. tagging all the cancers in red, the diseases in blue. With a decent visualisation you can see when the red and blue are close together – this is called a co-occurrence. Now you can ask a human to decide what the sentence is saying – is the cancer known to be treated by this drug, or resistant? This is the relationship you’re looking to find in wikidata terms.
Charles Matthews, Wikimedian in Residence at ContentMine, described the project as “an industrial scale version of the Find tool. Ctrl F gone mad.”
The first part of the project is to identify around 30,000 Open Access articles as a sample to work on. To do this, they need the help of the Wikimedia community, and especially medical professionals who know which articles in the literature would be most useful. Right now the list only has around 3-4,000 articles and is dominated by studies on infectious diseases.
Wikidata query visualised as a bubble chart showing breakdown of the Focus List and the diversity of subject areas represented.
In particular, the project is interested in looking at neglected diseases. These are diseases that have little research aimed at eradicating them because they often affect people in the world’s poorest countries. One example of this would be leprosy, which is nowhere near being wiped out (unlike Guinea Worm). A one country study of leprosy which would be specific about treatment and which drugs are used to treat it in that country would be useful as a reference. You can watch a video on Commons explaining neglected diseases here.
This means that there’s a systematic bias in the medical literature – rich people get more research on their diseases, and it’s important that we don’t simply reproduce this bias on Wikipedia.
So Science Source is developing a Focus List of medical literature with a concentration on neglected diseases, and needs the help of medical professionals to suggest good research papers in this area.
In order to add articles to this list, you need to add a particular property to the Wikidata item for the research article. The workflow is as follows:
Find the DOIs of papers you think should be part of this list. Pick, for example, the top 3 papers in a particular field, get the DOIs.
Science Source is done on wiki and people can participate, whereas WikiFactMine was an API which required people to be developers. So we need the Wikimedia community to help out, and especially medical professionals who are also Wikimedians.
If you know of any medical professionals who would be interested in helping out this important project to improve the quality and reliability of Wikipedia’s medical articles, please tell them about this project, or get in touch with Wikimedia UK or ContentMine for more information about how you can help. There’s also the ‘Facto Post’ mailing list which you can sign up for on Wiki to get updates about the project.
A Byzantine Tavern in Sergilla, part of the Dead Cities archaeological site – image by Syrian Inheritage CC BY-SA 4.0
I was scrolling Twitter when I came across a video of a fighter in Syria wasting ammunition to destroy an ancient Byzantine building.
Jihadists in Idlib, Syria, destroy what’s left of a Byzantium era archaeological building in Deir Sunbul.
The site is part of the “Dead Cities,” and is on UNESCO World Heritage List.https://t.co/LozBibwuIGpic.twitter.com/DE54KKOHQk
Deir Sunbul is part of the “Dead Cities” UNESCO world heritage site. Mekut, the poster of the video, informed me that the site had previously been damaged in the war. According to a report:
“The ruins at Deir Sunbul are scattered among modern houses, and include several villas, dozens of tombs, and a badly ruined church. Many of these structures bear inscriptions, usually of a Christian nature. The few dated inscriptions at Deir Sunbul are from the early 5th century. The two-storied villa in question was described by archaeologist Howard Butler Crosby in 1900 as “the most beautiful of all the residences in the region.” This villa bears no dated inscription, but its style suggests it was built in the 5th or 6th century.”
The Dead Cities Wikipedia page has quite a good list of all the sites in the Dead Cities, though I can’t help but think that if there was enough content, and enough sources online, that many of these sites should have their own Wikipedia pages. Perhaps they will eventually.
Anyway, at the moment, most of the sites recorded don’t have any media associated with them. Mekut, the poster of the tweet that peaked my interest, suggested I contact the historian Qalaat Al-Mudiq, who knows a lot about the area’s history. I discussed the problem of a lack of content being available for Wikipedia to record these sites adequately, and Qalaat showed me some photos he had taken in 2002 of buildings in the Dead Cities.
I explained how to upload these to Commons, and helped him to do so. You can see the category for photos of the Dead Cities here. I have also contacted some archaeological teams that were working in the area before the Syrian Civil War began, and hope that some of these contacts may have more content they are willing to release on Open Licenses.
According to Al-Mudiq, the “dead cities” “actually 150+ Byzantine villages in Jebal Zawiyah”, so I did a bit more searching and found a number of Western travellers who had been to the area before the war, including a Lonely Planet Editorial Director and a travel writer who wrote about the area for the Guardian in 2010. I’m following up with them to see if they have more photos that they could publish on Commons for us to use.
I find this kind of investigation quite interesting and rewarding, both from a journalistic perspective, and as an exercise in outreach to tell people how Wikipedia can be used to record these sites, and as a place where photos can be shared with the world. Most travel photography from the early years of digital photography, or from analogue cameras, will not be of a standard that makes it commercially marketable. If we can convince more people to publish their valuable photos of historical places on Commons, we can show the world how Open Licenses can make old photos that were not thought to be of much valuable useful for recording history and educating the world.
Most people don’t stop to think about copyright, and how it limits the usefulness of so much of the media we produce. That’s why we recently produced this short video explaining the history of copyright, which we encourage you to share.
Just think how many people there are with valuable historical photos who have never considered publishing them on Open Licenses. With places like Syria, the need for these images to be Open so we can record endangered cultural heritage is more important than ever.
Furthermore, we are gearing up for this year’s Wiki Loves Monuments competition. Syria, along with Jordan, Palestine, Lebanon and Iraq, are all participating countries in the competition. This means that if you have photos of heritage sites and monuments from these areas, you can upload them to Wikimedia Commons to participate in the competition.
Countries participating in WLM 2018 – image by Lokal_Profil CC BY-SA 4.0
We would love to hear about it if you have photos from these countries that you might like to upload. If you aren’t sure how, you can visit wikilovesmonuments.org.uk for more info, or simply get in touch with us via email or social media. So why not have a look through your drawers of old photos? There could be something in there which could be used to illustrate a Wikipedia page which would be read by millions of people.
Earlier this month, I was fortunate enough to be invited to the Project Launch of of GB1900; the first ever historical gazetteer of the entirety of Great Britain, capturing the isles between the years 1888 to 1914. I was invited by Humphrey Southall, Professor of Historical Geography at the University of Portsmouth. Dr Southall, who led the Project end to end, had previously delivered several Wikipedia in the Classroom courses, as part of his Geography modules at the The University of Portsmouth. The GB1900 project is unique and groundbreaking – or ground forming perhaps – in several ways. Most significantly because the project’s data points were entirely transcribed, with their coordinates then verified, by volunteers. And not only does the project begin with volunteers, bringing together the data for us all to see (as demonstrated below), the project’s data is open to use under Creative Common’s open licensing – the particular licensing depending on what form you would like to use the data in.
“GB1900 is a crowd-sourcing project to transcribe all text strings from the second edition six inch to the mile County Series maps published 1888-1914. The project is a collaboration between the National Library of Scotland, the Great Britain Historical GIS team at the University of Portsmouth, the Royal Commission on the Ancient and Historical Monuments of Wales, the University of Wales Centre for Advanced Welsh and Celtic Studies, the National Library of Wales and the People’s Collection Wales.
The final goal [was] to create the largest historical place-name gazetteer for Great Britain specifically including co-ordinates.”(1)
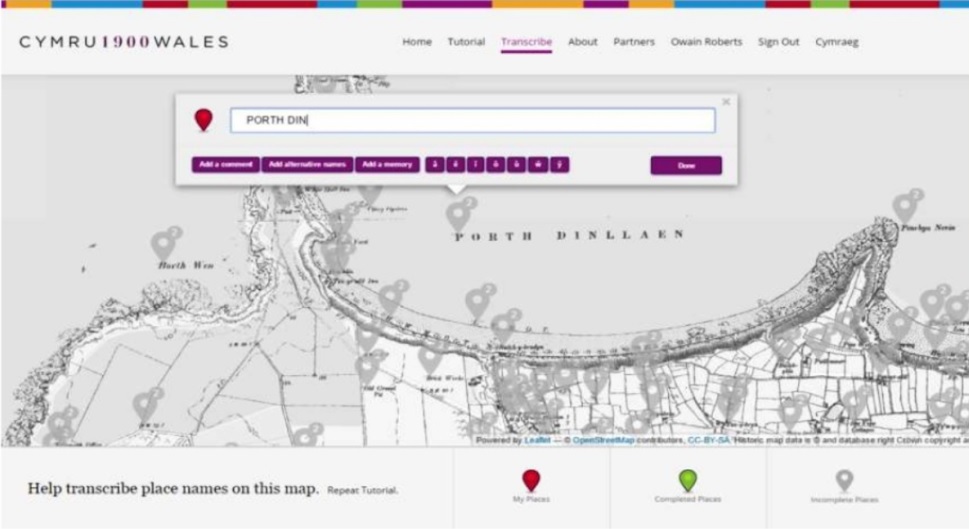
A screenshot of Cymru 1900’s user interface
A screenshot of Cymru 1900’s user interface
So why create a gazetteer of Great Britain, when you are trying to understand the lay of the land at a frozen point in history? Why not simply rely on old maps? And perhaps it’s worth detailing what entails a gazetteer to the non-geographers among us… A gazetteer is a ‘geographical dictionary’, to be used alongside a map or even an atlas, which gives more detailed description of the physical or geographic features of an area, at ‘land-level’. The presentation of the project began detailing the versatility of a gazetteer as a medium, stating that gazetteers “… are better than maps!” Historically, we have many more gazetteers to rely upon than maps, which are comparatively, a more recent phenomena – with maps only being commonplace from the 18th Century. Secondly, gazetteers are functional for walkers and navigating new areas – with descriptions of landmarks, as and when you come by them, (on a weekend stroll perhaps).
What were the team looking to achieve by transcribing a gazetteer or Great Britain, frozen in 1900? “We have three main aims. Firstly, to contribute to the overall development of “citizen science” by showing how working on particular local areas that matter to them affects the motivation of volunteers.” Following on from this, the team hoped that the project would encourage similar online crowdsourcing projects. Lastly, the project team wished to demonstrate how their work benefits the general public, “…we need to show not just that many people use our websites, but to report on what our sites help people to do.” (2)
The project’s process & outcomes
A need was identified for ‘a new historical gazetteer’ of Britain, as pre-existing historical gazetteers had partial data on either postcodes, features or parishes – but no completely descriptive gazetteer available as a whole. Discussions for such a project initially began in March of 2011, at first as ‘Cymru 1900- Historic Place names of Wales’, . After forming partnerships supporting the idea, the People’s Collection of Wales, the Centre for Advanced Welsh & Celtic Studies, National Library of Wales and the Royal Commission on the Ancient and Historical Monuments of Wales, decided to create a uniquely crowdsourced Welsh historical place name gazetteer. The collaboration then further partnered with the citizen science platform, Zooniverse, to host the development of the project’s bespokely required interface system. The website ‘Cymru1900wales’ was launched by October 2013, with transcription of the historic Ordnance Survey maps active until their completion in September 2016. The place names transcribed and verified by the volunteers in that time for the Cymru1900 gazetteer, were then also able to contribute to The List of Historic Place Names of Wales index, quickly being able to demonstrate the versatility of open- citizen-sourced data.
Soon after the successful completion of Cymru 1900, the project was then decidedly extended to attempt to transcribe the rest of Great Britain towards the end of 2015. In order for this to be achievable, it was recognised that several more volunteers were needed to be recruited, who would be fundamental in the execution of the project. The volunteers ideally would need to have an idea about transcription, and be interested in the History of Great Britain; the team turned to advertising part way through the project, through the ‘Who Do You Think You Are’ magazine’s ‘Transcription Tuesday’ initiative. This proved successful in adding some new faces to the team of dedicated volunteers who were enamoured by the project’s aims.
The team and volunteers proceeded to run with the GB1900 aims without funding, having officially launched their volunteer engagement in September 2016 and using high quality, historic map scans from the National Library of Scotland. A separate supporter site was then created for the volunteer’s to interface, building upon the successful format used for the Cmyru1900. The site designed so that volunteers could track the ‘contribution leaderboard’, and take a look at the maps as their data points grew in progress. At the project launch, by happenstance, I sat next to one of the many dedicated volunteers, who shared their delight not only at participating in the place-name subscription, but also the opportunity to share personal ‘place-memories’ of the areas they were working on, through the volunteer interface. By January 7th 2018, the whole of Great Britain at ‘1900’ had been completely transcribed. This of course was with great thanks to the 1000+ volunteers, several of which were presented to have given up to 20 hours a week to the project. Awards were given to the volunteers who had given the most hours, in the appropriate form of the printed ordnance survey maps, from the National Library of Scotland, featuring the regions that the volunteers has contributed the most to.
GB1900’s Vision of Britain data-sets
“In total, the volunteers located 2,666,341 strings on the maps, and contributed 5,500,339 transcriptions. It is hard to see how this could have been matched by an academic research team.” (3)
Following the presentation of the project, Dr. Southall and Paula Aucott, research associate of the project, used the opportunity to encourage the use of the open data – following the example of the proven versatility of the Cymru1900 project before hand. On the project’s website – it is made clear to whoever might interested, what forms of data are available e.g. the project’s ‘raw data’ or as ‘cleaned versions’ of the data – matched with the coordinates and modern district names of the transcribed place names – and what license they’re available under – e.g. CC by 0 & CC by SA, respectively. There were following presentations, giving insight to initial uses of the data set; by representatives from the University of Wales Centre for Advanced and Celtic Studies, demonstrating the historic linguistic research now attainable through the transcribed place names, and from The Ramblers, demonstrating how the data can be used for their Finding Historic Footpaths project.
Attending the project’s presentation was a clear demonstration of the possibilities of citizen science, with even just a small and dedicated team coordinating it’s growth and volunteer engagement behind the scenes. What was most poignant to me as an attendee of GB1900 launch, was the personal experience that was resonant with many of the volunteers who transcribed the coordinates of the gazetteer, with many focusing on areas where they had once lived or spent holidays. The project and it’s now open outputs reside within a wonderful overlap, whereby this new formation of data is not only useful, but has brought to life personal histories of places across britain, that were always there, simply waiting to be noted, and brought together.
Lorna Campbell reflecting on past OER conferences at OER18 in her keynote – The Long View: Changing perspectives on OER – image by Stinglehammer CC0
By Lorna M. Campbell, University of Edinburgh
Earlier this spring I was honoured to be invited to keynote at three open knowledge conferences in the UK and Ireland, which presented a great opportunity to highlight the work of the Wikimedia community to a wide and diverse audience.
The first event was the OER18 Open for All conference, which took place in Bristol in mid-April. Wikimedians have had a strong presence at the OER Conference since it was held at the University of Edinburgh in 2016, and this year was no exception. The conference, which now attracts delegates from across the world, featured no less than eight presentations and lightning talks focusing on different aspects of Wikimedia and education including Wikidata and the Semantic Web (Martin Poulter, WiR Bodleian Library), stories of Student empowerment and using Wikidata in the classroom (Ewan McAndrew, WiR University of Edinburgh), using Wicipedia as a platform to support Welsh language speakers and learners (Jason Evans, National Wikimedian, Wales) and using Wikipedia and Wikimedia Commons to support activism in cultural heritage (Anne-Marie Scott, University of Edinburgh).
I’ve been fortunate to attend every one of the OER Conferences since the event began in 2012 and my keynote focused on how the conference has examined and renegotiated what “OER” means over the years, I also looked at what we can do to ensure that open education is diverse, inclusive and participatory, and using examples of innovative initiatives from the University of Edinburgh, including the work of our Wikimedian in Residence, explored how we can engage students in open education practice and the co-creation of open education resources.
The following week I was at a very different event, the FLOSS UK Spring Conference in Edinburgh. The organising committee were keen to diversify both the scope and the gender balance of their event so I was invited to present a broad overview of the Open Knowledge landscape. It was also an the opportunity to highlight the problem of structural inequality and systemic bias in open communities, including Wikipedia and GitHub, and to highlight some of the positive steps Wikimedia is taking to tackle this problem, including the Wikimedians in Residence programme, and WikiProject Women in Red, and the success of Welsh language Wicipedia in being the first Wikipedia to achieve gender parity. I also highlighted the story of Open Knowledge advocate and Wikipedia editor Bassel Khartabil and the Memorial Fund that Creative Commons established to commemorate his legacy, because it demonstrates why it’s so important for all those of us who work in the broad domain of Open Knowledge to come together to break down the barriers that divide us.
In June I was in Galway for the CELT Symposium; not to be confused with the Celtic Knot Conference, which took place in Aberystwyth in July, the CELT Symposium is NUI Galway’s annual learning and teaching conference, and this year the theme was Design for Learning: Teaching and Learning Spaces in Higher Education. I was able to develop some of the themes I touched on at OER18 and FLOSS UK to look at what we mean when we talk about openness in relation to digital teaching and learning spaces, resources, communities and practices. I also explored the structural inequalities that prevent some groups and individuals from participating in open education and asked how open and equitable our open spaces really are, and who are they open to? Using innovative examples from our Wikimedian in Residence, I looked at how we can engage with students to co-create more equitable, inclusive and participatory open education spaces, communities and resources. It’s always a real privilege to be able to talk about our Wikipedia in the Classroom programme and to highlight the work that Ewan McAndrew has done to embed Wikipedia in a wide range of courses across the University of Edinburgh. Nobody communicates the value of Wikimedia in the classroom better than the students themselves so here’s Senior Honours Biology student Aine Kavanagh talking about her experience of writing a Wikipeda article as part of a classroom assignment in Reproductive Biology.
The title of my CELT talk, The Soul of Liberty – Openness, equality and co-creation, was paraphrased from a quote by Frances Wright, the Scottish feminist and social reformer, who was born in Dundee in 1795, but who rose to prominence in the United States as an abolitionist, a free thinker, and an advocate of women’s equality in education.
“Equality is the soul of liberty; there is, in fact, no liberty without it.”
The same could also be said of openness; equality is the soul of openness. If our open spaces and communities are not open to all equally, then really we have to question whether they are open at all. We need to identify the barriers that prevent some people from participating in the Wikimedia community, and we need to do what we can to remove these systemic obstructions. To me this is what openness is really about, the removal of systemic barriers and structural inequalities to provide opportunities to enable everyone to participate equitably, and on their own terms. And I believe this is why Wikimedia UK’s outreach activities and the work of our Wikimedians in Residence is so valuable, in helping to improve the coverage and esteem of Wikipedia articles about women and underrepresented minorities, and in redressing the gender imbalance of contributors by encouraging more women to become Wikimedia editors.
By Delphine Dallison, Wikimedian in Residence at the Scottish Libraries and Information Council (SLIC)
At the beginning of July, I attended the Celtic Knot 2018 conference at the National Library of Wales in Aberystwyth organised in partnership with Wikimedia UK. As a Wikidata novice, but enthusiast, I was excited to see that the conference had an entire strand dedicated to how Wikidata can be used to support minority language Wikipedias. As the new wikimedian in residence at the Scottish Library and Information Council, my hope was to shore up my own knowledge and skills in that area and both pick up some tips on how I could encourage librarians to work with Wikidata with their collections as well as some tools which would allow librarians to work on improving the Scots Wikipædia and the Gaelic Uicipeid.
My first positive impression of the Wikidata strand of the conference was that the presenters made no assumption of prior knowledge, thus making Wikidata accessible to the most novice of us attending the conference and so I will begin this post in much the same fashion with a basic introduction to Wikidata.
What is Wikidata?
Wikidata is a repository of multilingual linked open data, which started as a means to collect structured data to provide support for Wikipedia, Wikimedia Commons and the other wikis of the Wikimedia movement, but has since evolved to support a number of other open data projects.
Wikidata is a collaborative project and is edited and maintained by Wikidata editors in the same fashion as Wikipedia. The data collected in Wikidata is available under a CC0 public domain license and is both human and machine readable which opens it to a wide range of applications.
Data in the repository is stored as items, each with a label, a description and aliases if relevant. There are currently upwards of 46 million data items on Wikidata. Items are each given a unique identifier as a Q number (ie. Douglas Adams is Q42). Statements help expand on the detailed characteristics of an item and consist of a property (P number) and a value (Q number). Just like in Wikipedia, each statement can be given a reference, so people using the data can track where it was sourced from.
Based on the example below, one of the detailed characteristics of Douglas Adams is that he was educated at St John’s College. To translate the sentence Douglas Adams (Q42) was educated (P69) at St John’s College (Q691283) into data, you could portray it like this:
Item
Property
Value
Q42
P69
Q691283
Douglas Adams
Educated at
St John’s College
Figure 1: Datamodel in Wikidata, by Charlie Kritschmar (WMDE), CC-BY-SA
How can Wikidata support minority language Wikipedias?
As previously mentioned, Wikidata is a multilingual repository which supports all the languages supported by Wikipedia. Although English is the default, users can set their preferred language in the Preferences menu after logging in. Each Qnumber item on Wikidata has both a label and a description and you can select each one and see how many languages the label is translated into. The same principle works for properties. Wherever there isn’t a translation available for a label, description or property, it will revert back to English.
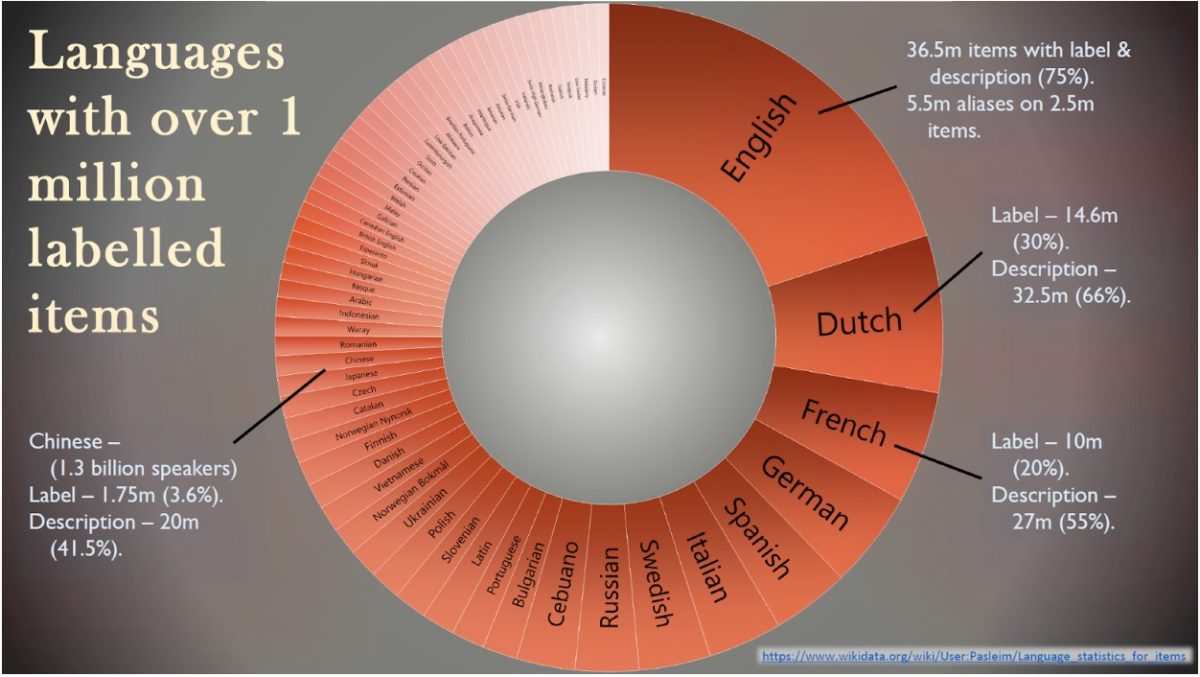
During the conference, Simon Cobb, visiting Wikidata scholar at the National Library of Wales, gave us an overview of the language gaps on Wikidata. As you can see from the graph below, the English version of Wikidata has 36.5 million labels (equivalent to 75% of the content held on Wikidata). After English, the figure quickly drops to 14.6 million labels for Dutch, 10 million for French and 8.7 million for German. UK minority languages such as Welsh, Scots and Scottish Gaelic average just over 1 million labels in their respective languages (just over 2%), meaning that all items without a translated label will automatically revert back to English or to the item’s Qnumber.
Figure 2: Languages with over 1 million labelled items, by Simon Cobb, CC-BY-SA
If we want to improve accessibility for minority languages on Wikidata, it is essential that we get more editors translating labels in their preferred languages so we can get a better representation of all languages on Wikidata. To help with this, Nicolas Vigneron, from the Breton Wikipedia, demonstrated how you can use the Translathon tool to quickly produce lists of labels missing in your language and add the translations directly in Wikidata by selecting the Qnumber you wish to translate. A new tool has since been developed on the same principle, the Wikidata Terminator, which gives a greater range of languages to work with.
Why translate labels on Wikidata?
You might be thinking that translating labels is all well and good for giving a better language representation on Wikidata, but how does it benefit editors who prefer to work on content on their language Wikipedia? We know that minority language communities are often small and disparate. Volunteer fatigue is a real and constant challenge, so why would you want to divert their efforts to translating labels on Wikidata rather than adding content to Wikipedia? The content held in Wikidata is human and machine readable. This is important because it means that using coding and tools, we can use Wikidata to automatically generate content on Wikipedia. A few of those tools were presented at Celtic Knot 2018.
Hady Elsahar gave us an introduction to the ArticlePlaceHolder tool. The concept behind this tool is that rather than having red links in their language Wikipedia to indicate articles that need created, editors can quickly and easily create a place holder for the article with content generated from Wikidata. The place holder would feature an image if available and a collection of statements associated with the item. The benefit to the reader is to be able to access pertinent information on a topic in their own language, thus relieving some of the strain on small communities of editors. The ArticlePlaceHolder can also be an incentive to new editors to create an article based on the facts available from Wikidata and supplement it with their own secondary research on the topic.
Figure 3: Example of the ArticlePlaceHolder tool in use on the Haitian Creole Wikipedia, CC-BY-SA
Pau Cabot also ran a workshop on how to automatically generate infoboxes on minority language Wikipedias by drawing the data from Wikidata. Infoboxes predate Wikidata and already foster a symbiotic relationship between Wikipedia and Wikidata. Wikipedia’s infoboxes hold basic data on a topic that is formatted to be compatible with Wikidata so they can be harvested to enrich Wikidata. However, a new trend is currently looking at how we can use Wikidata to generate the information displayed in Wikipedia’s infoboxes. This process can involve some structural work from admins on the Wikipedia’s infrastructure since each language Wikipedia have autonomy to curate infoboxes and other tools based on the wishes of their community. Pau Cabot talked us through the process that his admin team on the Catalan Wikipedia followed to decide on the infobox categories they would use across their Wikipedia, narrowing it down to a list of 8. Once the infrastructure was in place, the admins were able to generate easy templates that could be added to any relevant article and would automatically generate an infobox filled with data derived from Wikidata. Wherever the data’s labels do not currently exist in Catalan, the labels revert to the closest language available (Spanish if available, English as a last resort). However, the infoboxes also each offer the reader an easy edit tool, which allows the reader to translate the label directly in the infobox, whilst automatically adding the translation to Wikidata. This tool can therefore make the translation of labels accessible to Wikipedia editors who might not necessarily find their way onto the Wikidata project.
How can minority language communities contribute their own content to Wikidata?
Everything that we have discussed so far has been focused on how you can draw data from larger language Wikipedias to translate and add to smaller language Wikipedias, but of course minority language communities don’t simply want a Wikipedia that is a translated copy of the English Wikipedia. One of the chief objectives of the minority language Wikipedias is to act as repository of their own cultural capital and I would argue that working with Wikidata can only enhance the visibility of that culture. We need to start developing strategies with GLAMs and academic researchers to add more data on minority language cultures to Wikidata.
The National Library of Wales has already been doing work in this area and after adding 4800 portraits from their Welsh portrait collection, they also added all the associated metadata to Wikidata. This work was carried out in partnership with their national wikimedian in residence Jason Evans and their visiting Wikidata scholar Simon Cobb.
The idea of working with large sets of data and contributing them to Wikidata can seem daunting, however I was most inspired by the introduction that Simon Cobb gave us to the OpenRefine tool during the unconference sessions run on day two of Celtic Knot. OpenRefine is a tool developed by Google to help clean up messy data and in more recent editions of the tool (version 3.0), it has extensions added which allow the users to reconcile and augment their data with Wikidata as well as edit data directly in Wikidata and upload reconciled datasets to Wikidata.
As part of my residency with the Scottish Library and Information Council, I can definitely see the applications for this kind of tool to openly share the metadata on some of the Scots and Gaelic collections held in libraries across Scotland. I plan on testing the concept soon with a collaboration currently in development with professor Peter Reid from Robert Gordon University who is designing a Doric literature portal thanks to funding from the Public Library Improvement fund. Out of this collaboration, we hope to enrich the data available in Wikidata on Doric literature and Doric authors as well as create/improve articles on the topic in both the Scots and English Wikipedias. I hope to see more of these types of projects emerge in the future.
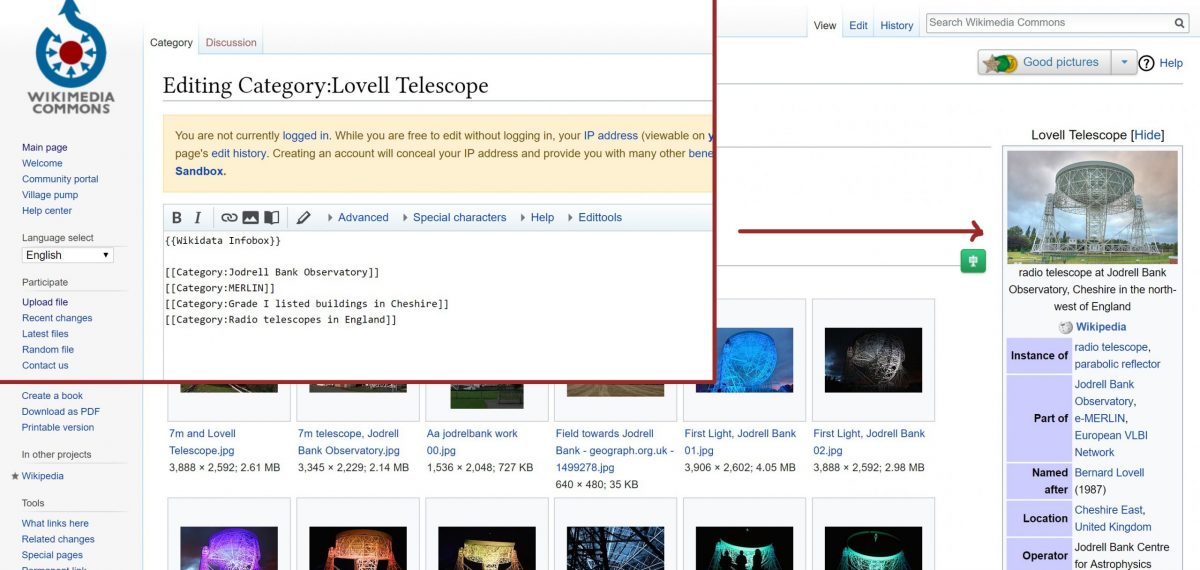
Image showing the infobox in source editor, and the resulting infobox on Commons.
Mike Peel is a UK Wikimedian who is running a session on the development of multilingual infoboxes on Wikimedia Commons at Wikimania 2018 in Cape Town. You can see the session information here.
Wikimedia Commons is a multilingual repository holding multimedia related to all possible topics. All language Wikipedias, as well as other projects, rely on the content hosted on Commons. However, MediaWiki is monolingual by default, so the defacto language on Commons is English, with category names in English — even for non-English topics.
As a result, it can be difficult for non-English speakers to understand the context and scope of a category. Sometimes manual descriptions and translations are present, along with various different utility templates, but the amount varies dramatically between categories.
Wikidata content, however, is inherently multilingual. Topics have Q-identifiers, and statements are made using properties, all of which are translatable. Structured Data on Commons (a Wikimedia project to ‘Wikidatafy’ Commons and improve its searchability) will soon use this system on file description pages – but it can also make the categories significantly easier to use by providing information relevant to the category in the user’s preferred language through an infobox.
Implementation
{{Wikidata Infobox}} is designed to be one infobox that work for all topics in all languages. It is written using parser functions, and it primarily uses [[User:RexxS]]’s Lua module [[Module:WikidataIB]] to fetch the values of nearly 300 properties from Wikidata, along with their qualifiers (and more can be added on demand). The label language is based on the user’s selected language.
The values are then displayed in various different formats such as strings, links, dates, numbers with units, and so on, as appropriate. The main image, as well as flags and coats of arms, are also displayed, along with the Wikidata description of the topic
Coordinates are displayed with Geohack and links to display the coordinates of all items in the category. Maps are displayed in the user’s language using Kartographer, with the map zoom level based on the area property for the topic. Links to Wikipedia, Wikivoyage, etc. are displayed where they are available in the user’s language. Links to tools such as Reasonator and Wikishootme are also included.
For categories about people, the infobox automatically adds the birth, death, first name and surname categories, along with tracking categories like ‘People by Name’. Authority control IDs are also displayed as external links, and ID tracking categories can also be automatically added.
Poster on Template:Wikidata Infobox by Mike Peel – image CC BY-SA 4.0
Roll-out
You can easily add the infobox to categories that have a sitelink on Wikidata: just add {{Wikidata Infobox}}!
The infobox was started in January 2018, with several test categories. An initial discussion on Commons’ Village Pump was very positive, and by the end of February it had been manually added to 1,000 categories, increasing to 5,000 by mid-March. Work on a bot to deploy the template was started in February, and was approved by the community by the end of April, when around 10,000 categories had infoboxes. The bot roll-out was started slowly to catch any issues with the infobox design, and particularly increases in the server load – but no server load issues arose.
In parallel, over 500,000 new commons sitelinks were added to Wikidata using P373 (the ‘commons category’ property) and monument ID matching, and many links to category redirects have been fixed. This has also caused many new interwiki links to be displayed in Commons categories.
In mid-June 2018, with the use of Pi bot and friends to add the infobox to categories, uses of the Wikidata infobox passed 1 million.
Next steps
The infobox continues to evolve and to gain new features, for example the implementation of multilingual interactive maps using Kartographer was quickly added to the infobox to make it available in over 600,000 categories displaying a map. More properties are being added to the box, although striking a balance between keeping the infobox small and adding relevant new properties is an ongoing discussion.
The infobox is not used where other boxes such as {{Creator}} and “category definition” are already in use; this could potentially change so that there is a uniform look across all categories. It is also not used for taxonomy categories due to different taxonomy structures on Commons and Wikidata.
Over 4 million Commons categories do not yet have a sitelink on Wikidata, so there is plenty of scope to add the infobox to more categories! The infoboxes will update and grow as more information and translations are added to Wikidata – so if you see wrong or untranslated information in them, correct it on Wikidata!
WikidataIB and the other tools used here (or even the entire infobox!) can easily be installed on other Wikimedia projects – providing that there is community consensus to do so!
By using this site, you agree we can set and use cookies.































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
_and_Jimmy_Wales_at_Wikimania_2018.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}