Conway Hall library – image by Jwslubbock CC BY-SA 4.0
Last weekend Conway Hall in central London hosted a Wikipedia editathon to improve pages on Wikipedia about 19th century pamphleteers and the subjects they wrotr about. Hundreds of Victorian-era pamphlets have been digitised and placed on CC0 licenses by Conway Hall library, and these are now being uploaded to Commons at the Category:Conway Hall digital collections.
These pamphlets are still being added, and if you want to help us improve Wikipedia by embedding them in relevant Wikipedia pages, you should also check out the GLAM/Conway Hall page for links to articles and subject areas on Wikipedia that need improving. Many of the pamphleteers who authored the publications have Wikipedia pages, and the pamphlets themselves often show the late 19th century thinking around subjects like religion, secularism, politics and society.
Conway Hall hosts lots of interesting events and talks on politics, music and history, all with a progressive, forwardthinking attitude to improving society. We are very grateful that the library has decided to publish its collection of digitised pamphlets on CC licenses so that they can be used on Wikipedia, and this will hopefully lead to a much wider audience for their collection.
There are lots of interesting pamphlets in the Conway Hall collection, exploring 19th century attitudes to railway nationalisation, Siam (Thailand), secularism, socialism and many other topics. There is still a list of articles in the GLAM page listed above that could be created on particular pamphleteers, and there are articles on pamphleteers like Gustav Zerffi, Charles Voysey and Annie Besant. which could have their newly uploaded pamphlets inserted into the articles from Commons.
We hope to do further editathons with Conway Hall library in future, and Alicia Chilcott from the library says that “we are planning to produce a special issue of our Ethical Record journal, focusing on the project and the various workshops that we have run as a part of it”.
We hope that the pamphlets will continue to be embedded in relevant articles on Wikipedia so they can help readers understand the progress of late 19th century thought on social and religious issues. If you improve an article with a document from Conway Hall’s collection, why not get in touch and tell us about it?
Wales has always had more than its fair share of ministers of religion, farmers… and educators!
During the Medieval period, the training of a ‘Prifardd’ (a registered Chief Poet), took ten years, but educating ordinary folk was by word of mouth. Around 1402, the last Welsh Prince of Wales, Owain Glyndwr, suggested founding a National University of Wales. Education, from the 17th Century onwards became linked to religion, as in many other nations. In 1674, the Welsh Trust (no article on en-wiki!) was formed in order to establish secondary schools throughout Wales and by 1681 there were 300 schools. This work was taken over by S.P.C.K. (Society for the Promotion of Christian Knowledge) early in the 18c. S.P.C.K. was formed in 1699 in London by a Welshman, Dr Thomas Bray, and 3 of the five main drivers were from Wales.
Many schools in Wales were also set up by charities so that the ordinary working-class person was given the opportunity to learn to read and discuss the Bible. Most teachers were curates, of which Griffith Jones, who taught 158,000 children to read in Welsh, must be one of the most famous today. By 1755 Wales had 3,495 schools, nearly all teaching through the medium of Welsh, as only around 5% of adults at that time could speak English.
At this time, Wales was one of the most literate countries in the world. The importance of education to the ordinary Welsh person during this time can not be over stressed. In England at this time, most ordinary folk were not given the chance to read and write whilst private school education flourished. Only a handful of private schools have existed in Wales, and as a result of this, today we can read what was written by the working-class people of Wales. For example, diaries kept by farmers are today being digitised and studied as they provide a comprehensive record of the weather at that time, information which is very relevant to those studying global warming.
During the 18th Century, the Welsh aspect within schools was lost: the English language was forced down the throats of children and corporal punishment became a daily routine for those who dared speak their mother tongue. My grandmother, who died 6 years ago, remembered it well! This inhumane practice was also used in Ireland, the Basque Country and other countries.
Today, for all children up to 16 years old, both Welsh and English languages are compulsory subjects. The Welsh Government aims to double the number of Welsh speakers by 2050 and ‘Wicipedia’ and ‘Wicidata’ are mentioned in their 2050 development plan, several times.
Wikipedia in Wales
In that context, let’s turn to a few Wikipedia milestones in Wales.
Having been appointed as Wales Manager for Wikimedia UK in July 2013, one of my first tasks was to co-organise the Eduwiki Conference at Cardiff. I invited Gareth Morlais, Digital Media Specialist at the Welsh Government, to open the conference and he spoke about the difficulty of getting minority languages recognised by internet giants such as Google. Gareth delivered his presentation in Welsh with live translation through headsets. The conference, and Gareth’s input, not only placed Wales on a global stage but also laid the foundation for the following work.
I approached the Coleg Cymraeg (the Federal University of Wales), which agreed to appoint a Wikimedian in Residence – the first full time WiR working in an university, worldwide. Mark Haynes was appointed in March 2014 and advised the Coleg on Creative Commons licences, which resulted in policy change. Since then, most of the academic work which goes on the Coleg Portal is on an open (CC-BY-SA) licence. This was a major breakthrough and even today, I’m yet to find a university which has opened their doors quite as wide.
The outcome of this is that when academic work is published, we can use it word for word on Wikipedia.
Edit-a-thon at Swansea University; 28 January 2015 – image by Llywelyn2000 CC BY-SA 4.0
On 28 January 2015, I organised the first ever Wikipedia Edit-a-thon in Wales at Swansea Library, and this was immediately followed by a Swansea University Edit-a-thon titled Women and Justice 1100-1750 in collaboration with Prof Deborah Youngs and Dr Sparky Booker from the Department of History and Classics. More on Swansea, later!
There are 22 ‘Language Ventures’ in Wales, one of which is Menter Iaith Mon (translation: ‘Anglesey language venture’). After a number of meetings with Menter Iaith Mon, in the Summer of 2016 they appointed a full time Wikipedian in Residence with funding from the Welsh Government. Aaron focused on the training of Wikipedia editing skills, and having been employed in the secondary sector for a few years, began training pupils on the island of Anglesey.
Menter Iaith Mon and myself wrote an application to the main examination board of Wales (WJEC) to formalise the training of wiki-skills as part of the Welsh Baccalaureate as one of the ‘Community Challenges’. This was successful and since September 2018 Aaron has worked with 6 schools in Anglesey and Gwynedd. In the next few years, we will encourage other language ventures and schools to follow suit.
Aaron’s work also dovetails with the Digital Competence Framework as well as an input into the GCSE curriculum: more on this in the next few months.
In 2016, Swansea University Senior Lecturer in Law, Dr Pedro Telles, and Richard Leonard-Davies began using the Wikimedia Dashboard; the project is currently in its 3rd year. Post-graduate students are drafting Wikipedia articles as part of their assessment.
In December 2018, the ”Companion to the Music of Wales” was published by Coleg Cymraeg (Federal University) and Bangor University. This is an encyclopedia that covers the history of music in Wales with over 500 articles ranging from early music to contemporary music, from folk singers to orchestras. As a direct result of our WiR at the Coleg, all text is on an open licence and we shall shortly be transfering it to Wikipedia. It is an authoritative encyclopedia and is the result of a collaborative project between the School of Music and Media at Bangor University and the Coleg Cymraeg. Editors: Wyn Thomas, Pro Vice-Chancellor, Bangor University and Dr Pwyll ap Siôn, Professor in Music.
Wicipop Editathon at Bangor University, 2017 – image by Llywelyn2000 CC BY-SA 4.0
Three weeks ago, I delivered a presentation at the first International Eduwiki at Donostia, Basque Country where some of these milestones were shared. I was glad to see that we are not alone in the work we are doing here in Wales. The Basque Country excels in wiki-education work at all levels. It was inspiring to see such wonderful work in many other languages in the field of open education in secondary and tertiary sectors.
The context and groundwork are solid. It is now time to build on this foundation. The Welsh Government are committed to this work in partnership with Wikimedia UK and others.
A new project is about to start shortly: a pilot project on how we can make it easier for children and young people to access Wicipedia Cymraeg.
Following a recent news report in a tabloid paper, which criticised websites including Wikipedia for not taking seriously enough the effects of online content on self-harm, Wikimedia UK would like to underscore the commitment of the Wikimedia community to addressing this issue.
Wikipedia aims to provide neutral, reliable encyclopedic content to its readers around the world. Wikipedia is written by independent volunteer editors and is open for editing by anyone. Editors use reliable sources to collaboratively write articles about a wide variety of topics, taking extra care to evaluate the information included about sensitive subjects in particular, such as those articles relating to suicide. Editors weigh these issues carefully to ensure information is presented from an educational, neutral viewpoint, and have also developed a guide for writing about suicide on Wikipedia.
The US based Wikimedia Foundation, which hosts Wikipedia and the other Wikimedia projects, has a Trust & Safety team that responds to requests from users that are identified as an imminent threat to life and limb. They have developed these processes in consultation with law enforcement and experts in emergency response. Their systems often function in coordination with other community-developed systems aimed at supporting the safety of all our readers and editors. For example, the Trust & Safety team at the Foundation has developed detailed guidance for editors to respond to threats of harm made on the Wikimedia sites.
A UK government health committee looking at the problem of online self-harm recently held a meeting of technology companies, to which neither the Wikimedia Foundation nor Wikimedia UK received an invitation. The Wikimedia Foundation has been in touch with the UK government to convey the seriousness with which they take the issue of online self-harm, and emphasised that they would welcome the opportunity to join meetings or conversations about this in future.
Wikimedia UK does not set editorial policy on Wikipedia, and does not have legal control of the site or responsibility for its contents. However, we are keen to work with relevant parties, where we can, to help address the complex issues surrounding online content and self-harm. In this context, we have previously offered to put the Samaritans in touch with UK-based editors to discuss these issues and to understand more about how editorial policies are developed on Wikipedia. We have also contacted the Department for Health and Social Care, who organised the recent summit on harmful online content, in case it would be helpful for them to engage with the local Wikimedia chapter on this issue.
If you have been affected by the issues discussed in this blogpost, you can call The Samaritans on 116 123.
1780: a time before the USA had gained its independence, before the first hot air balloon flights, and before Robert Burns had penned Auld Lang Syne. Also the year in which the Society of Antiquaries of Scotland was formed, with a mission to research and promote Scotland’s past.
Today we’re an independent charity with a global membership of over 2,700 members, (known as Fellows) with offices in the National Museum of Scotland, which was formed from the Society collection in 1851. And we’ve been promoting the discovery of Scotland’s past for the last 239 years by publishing books, journals, and excavation reports, funding research, holding events and lectures and running projects like the Scottish Archaeological Research Framework and Dig It!. All but the latest journals (and many of the sold-out books) are available open access and most events are free to attend (and recorded and uploaded to YouTube).
I LOVE IT WHEN A PLAN COMES TOGETHER
In order to take open access at the Society to the next level, we’ve recently appointed a Wikimedian-in-Residence: Dr Doug Rocks-Macqueen. Funded by Wikimedia UK, he works one day a week and we match this with Society staff time to help develop and run events and initiatives.
Doug is seconded to us from Landward Research, and is both a Fellow of the Society and Wiki-experienced, which means that he’s been able to hit the ground running. Key to Doug’s role is reviewing what the Society does and figuring out how we can feed that into the work of the Wikimedia Foundation. Part of this mission means ensuring that the Society team and our (global) Fellowship are Wiki-ready. Our first toe-in-the-water moment for this was hosting an edit-a-thon here in the Society offices, focusing on previous members of the Society (who include Sir Walter Scott don’tcha know).
THANK U, NEXT
After the success of our first edit-a-thon, we’re spreading our wings and holding the next one at Edinburgh Central Library. The Women in Scottish Archaeology | Wikipedia Edit-a-thon aims to address the lack of knowledge about women’s contributions to Scottish archaeology. If you’re in Edinburgh on 9 May, come along and find out more about our plans (and chow down on a free lunch).
We are very pleased to announce the recent appointment of three new trustees to Wikimedia UK’s board. Sangeet Bhullar, Jane Carlin and Marnie Woodward bring a range of skills and experience to the board including financial management, strategic partnerships and digital literacy.
Sangeet Bhullar joined the Wikimedia UK board in January 2019. She is the Founder and Director of WISE KIDS, which focuses on New Media Literacy Education, Digital Citizenship, Online Safety and Digital Well-being. In the last 17 years, Sangeet has worked with thousands of young people, parents and professionals in the UK, Singapore and Malaysia, addressing these themes. She is passionate about amplifying young people’s voices and about rights and agency in addressing risk, harm, opportunity and well-being online. Sangeet is based in Wales and is a member of a number of Welsh government and non-government committees. She will sit on Wikimedia UK’s Partnerships Advisory Board, helping to shape the chapter’s education programme.
Jane Carlin has been a trustee of Wikimedia UK since September 2018. She has served in a wide range of senior finance roles within the publishing and wider media sector, including educational publishing, and brings strong finance and compliance skills to the board. Jane is a chartered management accountant and is Chair of Wikimedia UK’s Audit and Risk Committee.
Marnie Woodward also joined the board in September 2018. She is a chartered management accountant, and has been involved in the charity sector as a finance director for several decades, having worked with the Dulwich Picture Gallery, the Mental Health Foundation, the Musicians Benevolent Fund and RPS Rainer among others. Previously she was a trustee and the chair of the Finance and Administration Committee of the Church Urban fund. She brings knowledge and experience of financial and organisational issues across a range of charitable enterprises. Marnie sits on the Audit and Risk Committee and is Treasurer for Wikimedia UK.
We are delighted to have attracted trustees of this calibre to the Wikimedia UK board, with such an impressive range of skills, knowledge and experience, and are looking forward to the new insights they can offer the charity over the next few years. There will be a number of additional board vacancies at Wikimedia UK this year, and we encourage members of our community to consider whether they could play a role within the governance of the organisation.
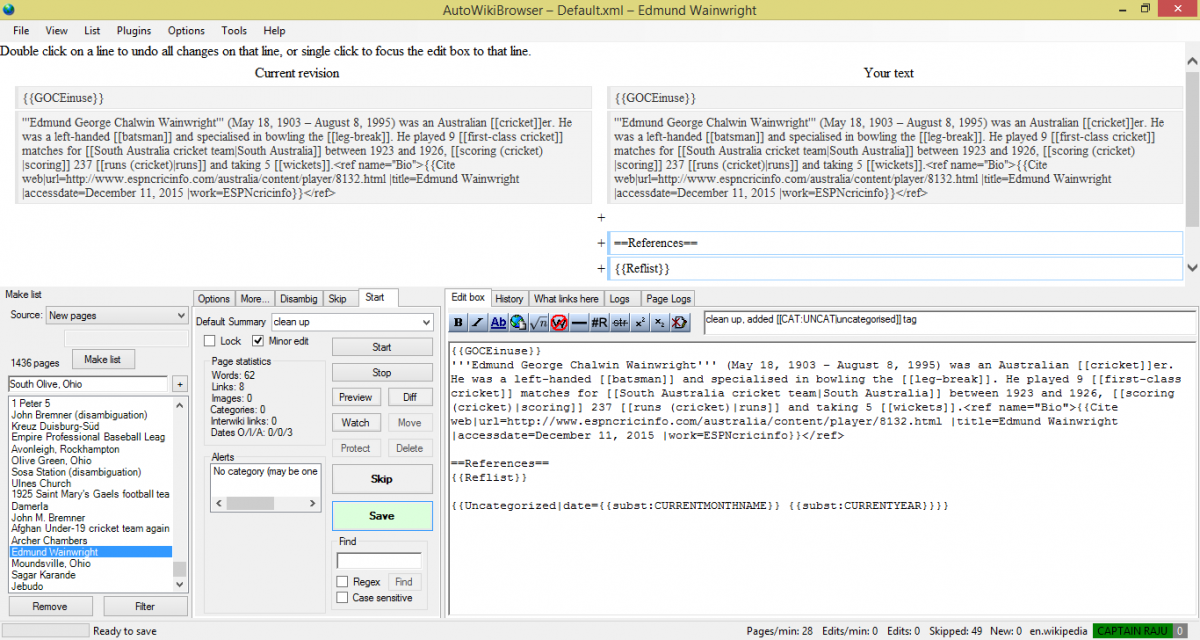
Screenshot of the AWB software – image by Magioladitis Reedy Rjwilmsi, GNU General Public License
Wikimedia UK has started running events to encourage long-time Wikipedia editors and those interested in becoming technically proficient at more complex tasks to gain skills that will allow them to improve Wikimedia projects.
In November we ran our first event on how to write a Featured Article. On May 7th, we will be running our second SkillShare event, focusing on how to use AutoWikiBrowser. AWB is “a browser that follows a user-generated list of pages to modify, presenting changes to implement within each of those pages, then progressing to the next page in the list once the changes are confirmed or skipped by the user.” It is intended to help editors make tedious and repetitive edits quickly and easily.
To use the software, you have to apply for permission on wiki, at this page. You need at least 250 non-automated edits in mainspace to get permission. I definitely recommend that if you want to come to our skillshare event that you do this in advance. You can then download the software here. Then follow the instructions on getting started.
There’s lots of other sources available online to understand how to use AWB like the video below.
So what can you do? You can auto tag templates, fix common typos, find and replace particular words, or import custom fixes. Once you’ve specified what you want to change, AWB will browse a set of selected pages, or a set of randomly generated ones, and then suggest changes based on your parameters. You can then review the suggested changes and decide to implement them or not.
You might want to check out the User Manual for AWB to get a better understanding about how to use it, but if you are a Wikipedia editor with a reasonable amount of experience who wants to better understand tools like AWB, you should consider coming to our next SkillShare, on Tuesday May 7. It takes place at the Wikimedia UK office in London, near London Bridge, Southwark and Blackfriars stations. Please sign up on the Eventbrite page to let us know you’re coming!
Shortly before 7pm on April 15 in Paris a devastating fire broke out in one of France’s most iconic buildings. The fire was extinguished after more than 12 hours, and while the stone walls still stood and movable artwork had been removed, the spire and roof had collapsed, causing extensive damage.
As a medievalist and someone who studies destruction I watched with grim interest, as did much of the world. The cathedral is a masterpiece of medieval art and architecture and welcomed 13 million visitors in 2018.
Within minutes of the first news reports, Wikipedia was being updated. At 7:19pm a short note was added to the article on Notre-Dame de Paris to say that it was on fire, and thirteen minutes later a separate page had been created to document the incident. Soon that page was available in more than 40 languages. At 8:21pm, Wikipedia’s Twitter account asked people to help document the event by taking photographs as it happened.
Lots of social media users commented that Wikipedia was quick to note that the building was on fire.
On 15 and 16 April, 1.2 million people read the page about the fire, and 16 million read the pages about the cathedral across all language versions. They came to Wikipedia to find out what was going on, and what had been lost.
Elite medieval architecture was designed to convey power and inspire awe; in cathedrals it was also intended to demonstrate piety and create something eternal. Cathedrals contain effigies, burials, and monuments to people who have long since passed but who wanted their memory to live on. Over Notre-Dame’s 850-year history it survived wars and revolution and became a symbol of French identity.
The fire has also caused some reflection about the loss of heritage sites elsewhere. For some people, it has brought back memories of fires at York Minster in 1984 and Windsor Castle in 1992. Further afield, the number of people reading the English Wikipedia’s list of destroyed heritage increased 27,000%, and there were more changes to that page in one day than in the past six months put together. This wasn’t just the work of one person either, it was more than 30 people (most of whom hadn’t edited the article before) who wanted to help. The page was of course updated to include Notre-Dame, but it was far more wide ranging. Historic events were documented from a dozen countries including Argentina, Ireland, and Turkey. If there was any doubt this interest in the loss of cultural heritage was triggered by the events unfolding at Notre-Dame de Paris, there was a common theme of destruction by fire in the updated coverage on the page. The entries are a mix of accidental and deliberate loss, and each tells a story which impacts a community. With the events in Paris, that community is international in scale.
The buildings around us are impermanent, and even thick stone walls which have stood for centuries can come under threat without prior notice. In these situations, Wikipedia acts as a form of public documentation. While the news records events as they unfold and the human impact, Wikipedia is there to provide the long view, with a detailed history of the cathedral and more than 7,000 media files with which to explore its fabric.
Wikipedia itself is impermanent, though its contributors try to create something which will endure the test of time. In other parts of the world projects such as New Palmyra aim to catalogue endangered heritage, creating digital models. There is no way to recover what has been lost, and physical recreations must be handled sensitively, but it does at least help document what has been lost.
If you have images of the Notre-Dame, or any other heritage sites, please do consider uploading them to Wikimedia Commons. From there they can potentially reach an audience of millions and the whole world can benefit.
Participants in the Wikimedia Education conference – image by Jon Urbe-Foku CC BY-SA 4.0
By Jason Evans, National Wikimedian for Wales.
In April 2019 the Basque Wikimedians User Group hosted the first Wikimedia + Education conference in Donostia. Using Wikipedia, and other Wikimedia projects in education is nothing new. There is a vibrant and well established community already engaged in a diverse range of projects from Wiki Clubs in primary schools to accredited Wikipedia based modules in universities. It’s hard to believe then that this is the first official, global, gathering of Wikimedians and educators involved in this work.
In its early days Wikipedia was shunned by educators – pooh-poohed as inconsistent and unreliable. But Wikipedia has long established itself as the go-to for information for millions of people in hundreds of languages, especially our young digital natives. In Wales for example, each time we ask school children, between 80-90% say they often use Wikipedia to help with their school work.
Gradually then, educators are beginning to realise that rather than ignore the gigantic free encyclopaedia in the room, they, with their students, can actually benefit from contributing to Wikipedia. This allows them to teach a whole raft of skills, such as research, digital literacy, collaboration and critical thinking. Contributing to Wikipedia also allows young people to feel like they are contributing something to society. Wikipedia gives their school work real world value. Rather than writing as essay, which is simply marked and filled away in a drawer, students can make a lasting contribution to collective knowledge in their language, which is accessible by anyone, anywhere in the world.
One thing that struck me at this conference was the diversity of participants. Education in Wikipedia is definitely not an English or even Western Centric concept, and often Education project facilitators, be they Wikimedia chapters and groups, universities, cultural institutions or even local governments, are motivated by the desire to increase content in a given language, and to increase the use of that language in the classroom. Activities in the Basque Country and Catalonia, areas keen to protect and promote their own unique language and cultural identity, are good examples.
There was a wide range of activities presented at the conference – With Robin Owain flying the flag for Wales with a presentation on progress at home. He also presented a fantastic video produced by Aaron Morris, Wikipedian in Residence with Menter Mon, highlighting his recent work with Welsh primary schools.
University level education activities were well represented at the conference with Wikipedia based assignments proving increasingly popular in universities around the World. In the UK, Edinburgh University has lead the way with this work and in Ireland Maynooth University has found Wikipedia contribution is hugely popular amongst students. The practice is also well establish in North America and many European countries.
Some Universities, drive participation with the help of a Wikipedian in Residence, or through training librarians. In Serbia universities have appointed Wiki ambassadors and the Catalans have a group of dedicated volunteers who coordinate projects within universities.
In Wales, higher education have been slow to embrace Wikipedia as a teaching tool. Individual lecturers at Swansea and Aberystwyth Universities have begun to explore the possibilities but there is definitely great potential for more engagement. Where we have had increasing success in Wales is in Secondary schools, thanks to the work of Aaron Morris. A number of schools are now teaching students digital competencies and Welsh language skills through Wikipedia editing as part of the Welsh Baccalaureate. Schools have even started forming Wiki Clubs and Primary Schools are also teaching their children about Wikipedia.
Presentations from educators in Argentina, Armenia, France, Catalonia, the Basque Country and others show that Wales is not alone in engaging younger children with Wikipedia editing. Katherine Maher, in her Keynote, pointed out that many of the movements most valuable contributors today began editing when they were thirteen or even younger. I tweeted her quote and had replies from editors who were as young as 8 years old when they made their first Wikipedia edit.
For many teachers, Wikipedia is merely a vehicle for effectively teaching a range of skills, which they would need to teach regardless. But for the Wikimedia movement and those in local governments with a mandate for supporting the growth of a language or culture, teaching Wikipedia can be seen as a long term investment in young people – instilling the notion that they can play an active role in the future of their language by contributing information rather than simply consuming it. This also helps build up the digital presence of a language which is essential for further investment in online infrastructure, by the likes of Microsoft and Google.
Armenian Wiki-clubs have been hugely successful with more than 30 clubs active around the country. Each club has its own trained coordinators and children contribute content they consider interesting, such as cartoons, films and music. Clubs also allow children to contribute through simple tasks to Wiktionary, Commons and other Wikimedia projects – which is a great way of lowering the barriers to entry. Club coordinators are responsible for checking the quality of all contributions of students. With only a small community of editors on the Welsh Wikipedia, the ability to manage and correct large amounts of new content from younger people would definitely need consideration here and the training of new trainers, be they teachers or community leaders and the production of more documentation and guidelines would be essential in replicating any such project at scale.
Participants at the Wikimedia Education Conference 2019 – image by Maialen Andres-Foku CC BY-SA 4.0
LiAnna Davis of the Wiki Education Foundation raised another issue which deserves consideration. Increasingly our young people are consuming knowledge through video rather than through reading. This might not be a bad thing, but it’s not something Wikipedia is very good at, especially in smaller languages. Should we be considering the creation of open video content as part of educational projects? At the very least this would complement and add value to a Wikipedia article, so i think it’s definitely something to consider.
From a Welsh perspective the approach of the Basque community is probably the most inspiring and the most relevant to our ambitions for the Welsh language Wikipedia. There are actually at least 10 active education programmes in the Basque Country. Some are small, but valuable programmes such as the work by Mondragon University to rewrite the lead to Wikipedia articles related to citizenship based on perceptions of school children – an exercise they call ‘Politics through Participation’. There is the Txikipedia, children’s Wikipedia project – the only children’s Wikipedia in the world to sit within a languages main Wikipedia, as well as an interesting community project aimed at encouraging locals to write about their local area. However it’s the work of creating content in universities and secondary schools which aligns best with our ambition to raise the standard of the Welsh Wikipedia for all, including the high percentage of young people who use it to find information for school work.
University students in the Basque country editing Wikipedia – image by Xabier Cañas CC BY-SA 4.0
Basque Wikimedians took the school syllabus for primary and secondary schools and, with the help of subject specialists, used it build a list of over 1800 articles which were vital for children’s education. They then partnered with Basque language universities to develop a program for students to create content relevant to secondary school pupils, and they partnered with secondary schools to write content relevant to primary schools.
In Wales the government has a long term strategy to grow the number of Welsh speakers to 1 million by 2050, and Welsh Wikipedia (along with Wikidata) is now officially recognised as an important part of that strategy. Implementing a strategy similar to the Basque Country would help the government achieve targets around digital competencies and the Welsh language in schools, whilst at the same time educating children about the topics being added to Wikipedia, and the output of this work becomes part of the open knowledge ecosystem in the Welsh language, where all Welsh speakers stand to benefit.
As we look to build on recent success in Wales, this conference has provided valuable insight into the incredible work already happening all around the world, from the perspective of educators and Wikipedians.
See more images from the Wikimedia Education conference 2019 on Wikimedia Commons.
By Martin Poulter, Wikimedian in Residence at the Bodleian Libraries, Oxford
The speed at which Wikidata is acquiring descriptions of paintings, sculptures and other museum holdings is impressive, but there is much further to go. It’s ironic that at the same time, we already have an enormous art database hiding in plain sight.
The problem is that what we have on Commons isn’t yet structured data: it’s not possible to get all images matching a chosen set of criteria; just the criteria that are pre-baked into the category system. Meanwhile, there are items from cultural institutions which are described in Wikidata and also have an image in Commons, but the two are not yet linked up. It’s crazy but it’s just the result of the order in which our platforms developed.
Structured data is coming to Commons in the longer term, but there are things we can all start right now. We can use the existing structured database – Wikidata – to improve the content and findability of photos on Commons.
It imports data about the artwork from Wikidata, just needing the relevant Wikidata identifier (a Q followed by some digits)
It keeps distinct the properties of the photograph and of the object in the photograph.
It has fields for photo date and photographer, distinct from the date and authorship of the item. If you take a photograph in 2019 of a statue from the 9th century, we want to avoid the ambiguity of a single date field..
The resulting entries are more multilingual, more detailed, have links to further information, and will automatically draw updates from Wikidata. Unit conversions (e.g. between inches and centimeters) are done automatically. In other words, we take some dull work from human beings and make the computer do it instead. All this while decreasing the amount of wiki-code on Commons!
If you’ve photographed a museum exhibit or piece of public art and shared the image on Commons, or if you’re interested in art works of a certain kind, I urge you to take a look through those photos and to search Wikidata to see if it describes what you photographed.
If the item does not yet exist on Wikidata, it’s surprisingly easy to add it. Take the Wikidata tours to learn about the interface.
This article was jointly authored by Thomas Shafee and Jack Nunn from the WikiJournals board, and edited by John Lubbock of Wikimedia UK.
The WikiJournals are a new group of peer-reviewed, open-access academic journals which are free to publish in. The twist is that articles published in them are integrated into Wikipedia. At the moment, there are three:
WikiJournals are also highly unusual for academic journals, as they’re free for both readers and authors!
What WikiJournals hope to achieve:
The aim of these journals is to generate new, high-quality peer-reviewed articles, which can form part of Wikipedia. As well as new articles, submissions can include existing Wikipedia pages, which are then subjected to the exact same rigour as any other submission.
The hope is that this new way of publishing peer-reviewed content will encourage academics, researchers, students and other experts to get involved in the process of creating and reviewing high-quality content for the Wikimedia project. It also allows participants a way of putting their contributions on their CV with an easily definable output (including DOI links and listing in indexes like Google Scholar).
When an article gets through the peer review process, there are two copies. The Journal copy can now be reliably cited and stays the same as a ‘version of record’ alongside the public reviewer comments. The Wikipedia version is free to evolve in the normal Wikipedia way as people update it over time, and is linked to the Journal article.
If this sounds like the sort of thing that you’d like to get involved in, support, or just spread the word on, there’s plenty of ways to contribute!
School projects
So here’s an example for a teacher. You have a class of 30 keen students who would normally all write an essay on a subject, have it read once, then never seen again. An alternative could be to have students in groups of 5 each chose a section of a neglected Wikipedia article to update and overhaul (there are millions of stub and start class articles to choose from). Each group writes a section of the article, then proofreads each others sections (WikiEdu has a great dashboard for this). Once the article is up to scratch, it’s submitted to the relevant WikiJournal who reaches out to experts in the topic to give in-depth feedback on what can be improved. If you and your students are able to fully address those comments then the article can be published and you and your students have just generated a new Wikipedia article read by thousands, and an academic article to put on their CVs!
Teachers who would consider using this method as an assessed class exercise can ask for advice from Wikimedia UK. We think that this workflow offers a useful alternative to simply having students write parts of Wikipedia articles in class, which may be harder to assess, and doesn’t provide a final product as tangible as a published journal article.
Academic outreach
The current priorities for the WikiJournals are to expand and improve representation on their editorial boards, and to invite article submissions. If you would like to volunteer in these roles, we encourage you to talk to the WikiJournal organisers.
If you are based in a UK academic institution at a course that has a strong strategic overlap with Wikimedia UK’s strategic priorities, you can also email education@wikimedia.org.uk to talk to us about providing advice on using WikiJournals as part of your course.
Individuals
The journals always welcome new submissions. Whether they’re written by a professor or a student, all go through the same process. You could get a team together to submit a brand new article. Or maybe you could overhaul and submit an existing Wikipedia page. You could even help translate an existing article.
They have a public discussion forum (typical for a wiki, unusual for a journal!) where you can share ideas for improvements, other projects they could reach out to or point out gaps in Wikipedia’s content where they could invite researchers to write an article.
Each journal has a twitter and facebook account (@WikiJMed, @WikiJSci and @WikiJHum) so feel free to chat with them there. You can even suggest social media posts or accounts to follow. Not into social media? Maybe put a poster in your university tearoom.
By using this site, you agree we can set and use cookies.































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}