




So you’re a business. You’ve got a company that’s number #3 in the UK at making spoons, or something like that, and you want to make sure that when people search for your company, they can see you’re legit because a Wikipedia page confers an aura of legitimacy on your noble pursuit of creating the best spoons in the land.
You tried to make a page for your spoon business before, but for some reason it disappeared. No doubt the anti-spoon lobby have got their knives out for you in their cynical attempt to stop people using your quality products. You’ve found the charity responsible for Wikipedia in the UK (that’s us!) and you want to know how you can get your spoon business listed on Wikipedia.
I’m afraid that we may have some bad news for you. You see, Wikipedia is not a business directory. It’s not the Yellow Pages or whatever website has put the Yellow Pages out of business. So you probably need to stop and think ‘is my business notable enough to be in an encyclopaedia?’ It’s estimated that there are somewhere around 200 million companies in the world, so only very few of these will be famous enough to appear in an encyclopaedia.
Maybe you don’t know the answer because you’re not sure what makes something notable enough to be on Wikipedia. Well, luckily we have a set of Notability guidelines for that.
The basic criteria for notability is that “a topic has received significant coverage in reliable sources that are independent of the subject”. So I’m afraid that links to your own site, quotes in articles about another subject, or references to other self-published sources like blogs, petitions or social media posts just won’t meet this standard.
[pdf-embedder url=”https://wikimedia.org.uk//wp-content/uploads/2018/10/Verifiability_and_Notability_-_tutorial.pdf”]
A presentation on verifiability and notability – Wikimedia Commons CC BY-SA 4.0
This standard isn’t supposed to be easy to meet. Your business might be doing really well, it might make the biggest spoons in Britain, but if you’ve not had the Times, or at least the local newspaper down to cover your amazing spoon production in an article which is specifically about your business, then as far as Wikipedia is concerned, it’s not going to be notable enough. But don’t get disappointed. If you want your spoons to be famous, you need to concentrate on getting some media coverage for those spoons. Wikipedia can only cover what has been already published elsewhere.
If your company is notable, it’s likely that someone will eventually get around to creating a page for it. You’re just going to have to be patient. If you try to create the page yourself, without really understanding the core rules of Wikipedia, you might make some mistakes, like putting in Non-Neutral Point of View language, which will show others that you might be connected to the subject matter, and result in the article’s deletion for Conflict of Interest (CoI) editing.
You should also most definitely not pay someone to create a page for you. Paid editing, without a declaration that someone is being paid to edit, is against the rules. If the page for a company keeps getting made and then deleted, editors may ban the creation of the page indefinitely. In 2015 Wikipedia editors uncovered a group trying to make money by scamming businesses by telling them they could make and protect their company’s Wikipedia articles.
The main lesson in this is that if you are going to use Wikipedia properly, you really have to understand how it works. You can’t just stumble into it and start changing important things without appreciating what you’re allowed to change and what kinds of edits are acceptable. On English Wikipedia, you can’t even create new articles anymore without having a registered account with a certain number of edits.
We recognise that this can be frustrating and offputting to some businesses who could theoretically have good reason to interact with Wikipedia. However, there are things your company could consider doing to make it more likely that someone will create a page for you. You could consider releasing photos of your company or its products under an Open, Creative Commons license, meaning that these photos can be used on Wikipedia.
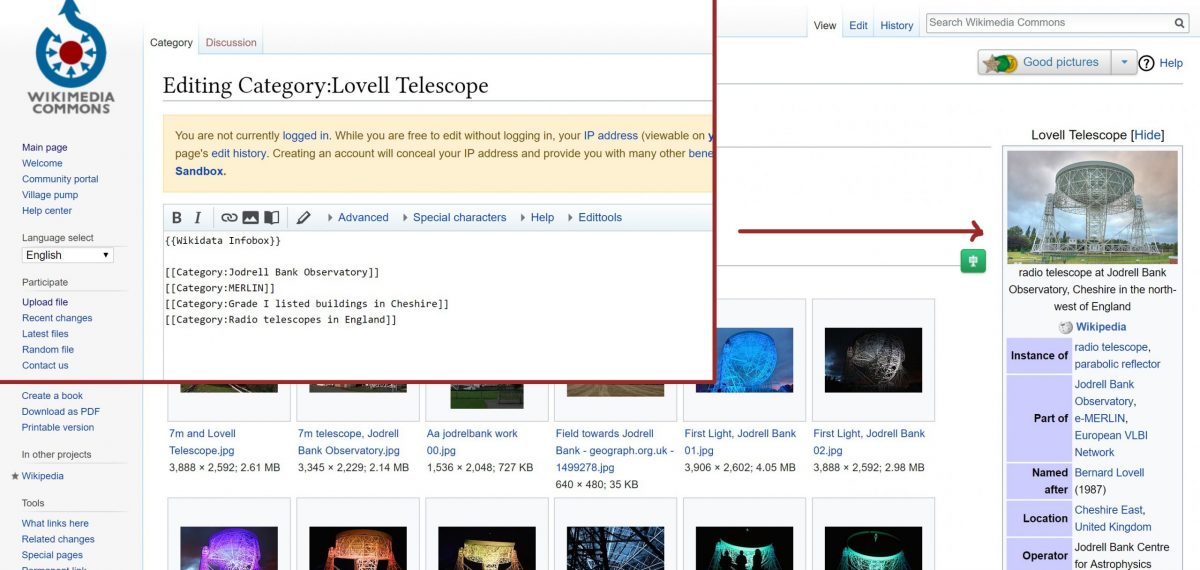
All the content on Wikipedia is shared on Open Licenses, so we can’t use any media about your company unless you publish it specifically on an Open License. The Welsh music label, Sain Records, released the cover art of many of their Welsh-language records on Open Licenses, along with 30 second clips of some of their artists songs. This means there is now much better coverage of the company and its products on Wikipedia.

I have been trying to do outreach to the music industry to encourage them to donate content, like photos of their artists, which Wikipedia editors can use to improve pages on notable musicians. There are lots of black and ethnic minority musicians who don’t have pages on Wikipedia, and we would like to change that. Again, we don’t encourage people who work for music companies to make pages about their artists, but if those companies would like to work with Wikimedia UK, we could organise Wikipedia editing workshops for fans of the artists, and use photos donated by the artists’ companies to create pages for notable people who deserve to be on the encyclopaedia.
We’ve already had a very fruitful collaboration with the Parliamentary Digital Service, who released official parliamentary photos of MPs in 2017, and you will now see that most MPs pages use their official photograph in the infobox on the right of the page.
The best way to learn how Wikipedia works is to get involved. Come to our events. Come to meetups to talk to other Wikimedians and ask their advice. The community is huge, and has over the past 18 years created a complex set of rules to govern the living, constantly changing nature of Wikipedia. We think it’s an amazing achievement, and that’s why we treat it as so much more than an advertising platform.


























{kind=link}
{kind=link}
_and_Jimmy_Wales_at_Wikimania_2018.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
.png){kind=link}